
Введение в методы параллельного программирования - ответы
Количество вопросов - 249
Соседние вершины в кольцевой топологии отображаются кодом Грея:

Нижняя оценка необходимого количества операций для упорядочивания набора из n значений определяется выражением:
Метод покоординатной маршрутизации в приложении к топологии типа гиперкуб состоит:
При применении параллельных алгоритмов быстрой сортировки одним из основных моментов является:
Номер процесса в рамках MPI именуется:
Сложность последовательного алгоритма Флойда имеет порядок:
Операция широковещательной рассылки данных это:
Задача редукции определяется в общем виде как:
Какая из приведенных в лекции топологий (при одинаковом количестве процессоров) обладает наименьшей стоимостью:
Основное отличие комбинаторных алгоритмов от геометрических методов, применяемых для решения задачи оптимального разделения графов, заключается:
Какая коммуникационная операция используется при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы на вертикальные полосы?
Пусть есть задача вычисление суммы следующего вида  . Пусть N = 8 и применяется каскадная схема, аналогичная схеме описанной в лекции для суммирования элементов вектора. Какая в этом случае минимально возможная высота дерева модели вычисления:
. Пусть N = 8 и применяется каскадная схема, аналогичная схеме описанной в лекции для суммирования элементов вектора. Какая в этом случае минимально возможная высота дерева модели вычисления:
Для распределения вычислений между процессорами в вычислительных системах с распределенной памятью необходимо:
Под мультикомпьютером понимается:
Матрица смежности это:
На одном из этапов метода покоординатного разбиения для решения задачи оптимального разделения графов:
Какие способы распределения элементов матрицы между процессорами вычислительной системы изложены в данной лекции?
В результате выполнения одной итерации параллельного алгоритма быстрой сортировки исходное множество процессоров разделяется на:
Пусть есть задача вычисления произведения всех элемента вектора 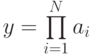 . Пусть N = 6 и применяется каскадная схема с минимально возможной высотой дерева модели вычисления. Чему в этом случае равно ускорение при использовании неограниченного числа вычислительных элементов:
. Пусть N = 6 и применяется каскадная схема с минимально возможной высотой дерева модели вычисления. Чему в этом случае равно ускорение при использовании неограниченного числа вычислительных элементов:
На основании результатов экспериментов, представленных в лекции, можно сказать, что наибольшее ускорение демонстрирует:
Распределенные вычислительные системы:
В рассматриваемой учебной задаче по решению задачи Дирихле при использовании разделенной памяти, какие возможны способы разделения данных?
Под коллективными операциями в MPI понимаются:
Для разбиения графа на k частей в методе бинарного деления для решения задачи оптимального разделения графов необходимо:
На каждой итерации обратного хода метода Гаусса используется
Показатели ускорения и эффективности параллельного алгоритма Прима имеют вид (без учета затрат на передачу данных):
В модели вычислений дуги графа определяют:
В методе передачи пакетов:
Из представленных в лекции алгоритмов, лучшей масштабируемостью обладает:
Какой способ наиболее эффективен при подсчете общей для всех процессоров погрешности вычислений, которые используются в параллельной реализации метода сеток на системах с распределенной памятью?
Какую компьютерную систему можно отнести к суперкомпьютерам:
Под кластером обычно понимается:
В основе классификации вычислительных систем в систематике Флинна используются:
Типовые топологии сети передачи данных определяются:
Какая из приведенных в лекции топологий (при одинаковом количестве процессоров) обладает наибольшей связностью:
В модели вычислений вершинами графа являются:
Эффективность параллельных вычислений – это:
В модифицированной каскадной схеме:
Пусть есть задача вычисление суммы следующего вида 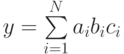 . Пусть N = 4 и применяется каскадная схема, аналогичная схеме описанной в лекции для суммирования элементов вектора. Какая в этом случае минимально возможная высота дерева модели вычисления:
. Пусть N = 4 и применяется каскадная схема, аналогичная схеме описанной в лекции для суммирования элементов вектора. Какая в этом случае минимально возможная высота дерева модели вычисления:
Пусть в решаемой задаче последовательная часть составляет четыре единицы времени, а часть, допускающая линейное распараллеливание, шесть единицы времени. Если использовать закон Амдаля, сколько потребуется процессоров для достижения ускорения в два раза:
В методах покоординатной маршрутизации поиск путей передачи данных осуществляется:
Основной набор параметров, описывающих время передачи данных, состоит из следующего набора величин:
Метод передачи пакетов в большинстве случаев приводит к:
Увеличение вершин:
Топология полный граф сети кластерной вычислительной системы может иметь ограничения на:
Процессы параллельной программой в рамках MPI:
Под коммуникатором в MPI понимается:
Завершение функции MPI_Send означает, что:
Прием сообщения при помощи функции MPI_Recv может быть инициирован:
В синхронном режиме передачи завершение функции отправки сообщения происходит:
Завершение вызова функции неблокирующего обмена приводит:
Обобщенная передача данных от всех процессов всем процессам может быть описана как:
Производным типом данных в MPI называется:
При индексном способе новый производный тип создается как:
MPI поддерживает топологии вида:
Распределение подзадач между процессорами должно быть выполнено таким образом, чтобы:
Граф "подзадачи – сообщения" представляет собой:
Канал передачи данных можно рассматривать как:
При выборе способа разделения вычислений при прочих равных условиях нужно отдавать предпочтение:
Для локальной схемы передачи данных характерно:
Основным показателем успешности выполнения этапа распределения подзадач между процессорами является:
При выполнении параллельного алгоритма, основанного на разделении матрицы на горизонтальные полосы, сбор данных результирующего вектора выполняется при помощи:
Для эффективного выполнения параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы на вертикальные полосы, необходимо, чтобы процессоры вычислительной системы были объединены в топологию:
С ростом числа процессоров, согласно теоретической оценке, наибольшее ускорение демонстрирует:
Рассмотрим задачу перемножения матрицы на вектор. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время 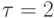 нсек. Латентности сети
нсек. Латентности сети 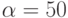 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на строки чему будет равно теоретическая эффективность при использовании 4 процессоров:
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на строки чему будет равно теоретическая эффективность при использовании 4 процессоров:
Рассмотрим задачу перемножения матрицы на вектор. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети 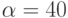 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы блоки (количество блоков по строкам и по строкам равно и равно
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы блоки (количество блоков по строкам и по строкам равно и равно 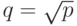 , где p – количество процессоров), чему будет равно теоретическая стоимость при использовании 4 процессоров:
, где p – количество процессоров), чему будет равно теоретическая стоимость при использовании 4 процессоров:
Какие схемы разделения данных используются при разработке параллельных алгоритмов умножения матриц?
Какие коммуникационные операции используются при выполнении параллельного алгоритма Фокса?
Для эффективного выполнения параллельного алгоритма умножения матриц, основанного на ленточной схеме разделения данных, необходимо, чтобы процессоры вычислительной системы были организованы в топологию:
Из представленных в лекции алгоритмов, лучшей масштабируемостью обладает:
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети 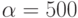 нсек. Пропускная способность сети
нсек. Пропускная способность сети  Mбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на ленты, чему будет равно теоретическое ускорение при использовании 4 процессоров:
Mбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на ленты, чему будет равно теоретическое ускорение при использовании 4 процессоров:
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 200x200. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать алгоритм Фокса, чему будет равна теоретическая эффективность при использовании 4 процессоров:
Какое расположение вектора правых частей и вектора неизвестных используется при реализации параллельного алгоритма Гаусса:
На каждой итерации прямого хода алгоритма Гаусса для нахождения ведущей строки используется
За основу организации параллельных вычислений при реализации метода сопряженных градиентов выбирается параллельное выполнение операции умножения матрицы на вектор, потому что:
Рассмотрим задачу поиска решения системы линейных уравнений. Пусть размер матрицы системы линейных уравнений 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма Гаусса использовалось 4 процессора, то какое в этом случае достигается теоретическое ускорение:
Рассмотрим задачу поиска решения системы линейных уравнений. Пусть размер матрицы системы линейных уравнений 200x200. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма сопряженных градиентов использовалось 4 процессора, то какая в этом случае достигается теоретическая эффективность:
Внутренняя сортировка это:
Базовая операция "сравнить и переставить" состоит из:
Трудоемкость алгоритма пузырьковой сортировки оценивается выражением:
Основными отличиями параллельного алгоритма Шелла от метода чет-нечетной перестановки являются:
В худшем случае трудоемкость быстрой сортировки оценивается выражением:
Оптимальная стратегия выбора ведущего элемента при применении параллельных алгоритмов быстрой сортировки состоит в выборе такого значения ведущего элемента, при котором:
Один из этапов параллельного алгоритма быстрой сортировки состоит том, что:
При выполнении алгоритма обобщенной быстрой сортировки в качестве ведущего элемента обычно выбирается:
Взвешенный граф это:
Задача поиска всех кратчайших путей обычно формулируется как:
Один из возможных способов агрегации вычислений для увеличения эффективности параллельного алгоритма Флойда состоит:
Задача нахождения МОД формулируется как:
Трудоемкость нахождения МОД характеризуется:
Задача оптимального разделения графа состоит в разбиении вершин графа на непересекающиеся подмножества:
Метод бинарного деления для решения задачи оптимального разделения графов заключается:
Метод покоординатного разбиения для решения задачи оптимального разделения графов отличается от метода бинарного деления тем, что:
Комбинаторные методы решения задачи оптимального разделения графов обычно обеспечивают:
С какими проблемами сталкивается программист, разрабатывая параллельные программы для систем с общей памятью?
Каким образом обеспечивается балансировка вычислительной нагрузки процессоров для параллельных алгоритмов для систем с общей памятью,?
Для параллельных алгоритмов для систем с общей памятью при проведении вычислительных экспериментов может наблюдаться сверхлинейное ускорение. Каковы возможные причины достижения этого эффекта?
Какие проблемы параллельного программирования являются общими для систем с общей и распределенной памятью?
В чем состоит первая проблема, которую приходится решать при организации параллельных вычислений на системах с распределенной памяти?
Какие механизмы передачи данных могут быть задействованы?
Для постановки задачи в системе ПараЛаб необходимо выбрать:
В каком из режимов можно провести вычислительный эксперимент?
При анализе результатов проведенных экспериментов пользователю предоставляется возможность:
Какие режимы передачи данных поддерживает система имитационного моделирования ПараЛаб:
На каких топологиях сети в системе ПараЛаб не реализованы алгоритмы обработки графов:
Помимо выполнения экспериментов в режиме имитации, в системе ПараЛаб предусмотрена возможность проведения реальных экспериментов в режиме удаленного доступа к вычислительному кластеру. Какие возможны операции после выполнения реальных параллельных вычислений:
В коллективных операциях передачи данных обязаны принимать участие:
С ростом числа процессоров, наибольшее ускорение демонстрирует:
При векторном способе новый производный тип создается как:
При проведении серии экспериментов системой ПараЛаб может автоматически варьироваться:
Каскадная схема используется для:
Режим разделения времени:
В модели Хокни используются параметры:
К числу суперкомпьютеров относятся:
Пусть перед программистом поставлена задача перемножения матрицы на вектор. Размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и в системе занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на блоки (количество блоков по строкам и по строкам равно и равно , где p – количество процессоров), чему будет равно теоретическая эффективность при использовании 4 процессоров:
Время начальной подготовки (tн) характеризует:
На каких топологиях сети в системе ПараЛаб реализована быстрая сортировка:
В статической схеме передачи данных:
Рассмотрим задачу перемножения матрицы на вектор. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на строки чему будет равно теоретическое ускорение при использовании 2 процессоров:
Для снижения сложности моделирования и анализа параллельных методов операции передачи и приема данных считаются выполняющимися:
Уплотнение дуг это:
В рамках системы ПараЛаб какие допускаются схемы выполнения вычислений при проведении экспериментов:
Под параллельной программой в рамках MPI понимается:
Для того чтобы выбрать ведущий элемент в параллельном алгоритме быстрой сортировки выполняются следующие действия:
Рассмотрим задачу поиска решения системы линейных уравнений. Пусть размер матрицы системы линейных уравнений 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети  Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма Гауса использовалось 4 процессора, то какая в этом случае достигается теоретическая эффективность:
Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма Гауса использовалось 4 процессора, то какая в этом случае достигается теоретическая эффективность:
Какие из перечисленных ниже классы задач поддерживает система имитационного моделирования ПараЛаб:
Для эффективного выполнения алгоритма Фокса необходимо, чтобы процессоры вычислительной системы были организованы в топологию:
Коллективные операции MPI:
Функция MPI_Recv:
Кластерные вычислительные системы:
Количество выполняемых операций при определении номера ближайшей вершины до охватывающего дерева и корректировке расстояний после расширения МОД ограничивается сверху величиной:
На каких топологиях сети в системе ПараЛаб реализованы алгоритмы перемножения матриц:
Общее число итераций параллельного алгоритма чет-нечетной сортировки при использовании p процессоров равно:
Какие алгоритмы обладают наилучшими теоретическими показателями ускорения и эффективности (в случае, когда не учитываются затраты на передачу данных между процессорами):
К основным преимуществам кластерных вычислительных систем относится:
Под мультипроцессором понимается:
К числу характеристик топологии сети передачи данных относятся:
Пусть есть задача вычисления суммы следующего вида  . Пусть N = 6 и применяется каскадная схема с минимально возможной высотой дерева модели вычисления. Чему в этом случае равна стоимость вычислений при использовании восьми вычислительных элементов:
. Пусть N = 6 и применяется каскадная схема с минимально возможной высотой дерева модели вычисления. Чему в этом случае равна стоимость вычислений при использовании восьми вычислительных элементов:
Пусть в решаемой задаче последовательная часть составляет четыре единицы времени, а часть, допускающая линейное распараллеливание, шесть единицы времени. Если использовать закон Амдаля, какая достигается эффективность, если используются три вычислительных элемента:
Алгоритмы маршрутизации определяют:
Для рассылки от одного процессора всем остальным процессорам сети при использовании топологии типа гиперкуб достаточно (N=log2p):
Двоичный код Грея используется для определения соответствия между:
Для кластерных систем характерна:
Минимально необходимый набор операций для организации информационного взаимодействия между процессорами в вычислительных системах с распределенной памятью включает в себя только:
Указание используемого коммуникатора является:
Режим передачи по готовности может быть использован только если:
Функция блокирующего ожидания завершения одного обмена в MPI называется:
Сигнатурой производного типа в MPI именуется:
H-векторный и H-индексный способы создания данных отличаются от векторного и индексного способов тем, что:
Топология типа тор в MPI является частным видом топологии типа:
Качество разрабатываемых параллельных методов определяется:
Рассмотрение графа "подзадачи – сообщения" концентрирует внимание на вопросах:
При асинхронном способе взаимодействия участники взаимодействия:
При разработке параллельных алгоритмов для матричных вычислений за основу выбирается разделение данных, потому что:
Какая коммуникационная операция используется в параллельном алгоритме умножения матрицы на вектор, основанном на блочном разделении матрицы, для получения блоков результирующего вектора на процессорах, составляющих одну строку процессорной решетки?
Для эффективного выполнения параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы на горизонтальные полосы, необходимо, чтобы процессоры вычислительной системы были объединены в топологию:
При разработке параллельного алгоритма умножения матриц, основанного на ленточной схеме разделения данных, может быть использован подход:
Какие коммуникационные операции используются при выполнении параллельного алгоритма Кэннона?
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы имеют тип double и в системе занимают w = 8 байт. Если при распараллеливании использовать алгоритм Кеннона, чему будет равно теоретическое ускорение при использовании 4 процессоров:
За основу организации параллельных вычислений при реализации метода сопряженных градиентов выбирается:
Рассмотрим задачу поиска решения системы линейных уравнений. Пусть размер матрицы системы линейных уравнений 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети 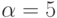 нсек. Пропускная способность сети
нсек. Пропускная способность сети 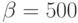 Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма сопряженных градиентов использовалось 4 процессора, то какое в этом случае достигается теоретическое ускорение:
Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма сопряженных градиентов использовалось 4 процессора, то какое в этом случае достигается теоретическое ускорение:
Базовая операция "сравнить и переставить" обычно используется в:
Общее наименьшее количество итераций параллельного алгоритма Шелла равно:
Алгоритм быстрой сортировки основан на:
Три схемы распараллеливания алгоритма быстрой сортировки различаются:
Показатели ускорения и эффективности параллельного алгоритма Флойда имеют вид (без учета затрат на передачу данных):
При горизонтальном разбиении матрицы исходных данных на каждой итерации алгоритма Флойда потребуется передавать между подзадачами:
Для разбиения графа на k частей в методе бинарного деления для решения задачи оптимального разделения графов необходимо выполнить:
Какие способы распределения данных между процессорами вычислительной системы изложены в данной лекции?
Вычислительный эксперимент в системе ПараЛаб – это:
Эксперименты в режиме имитации возможно проводить:
При построении графических зависимостей для экспериментов, проведенных в режиме имитации, используются:
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 200x200. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы имеют тип double и в системе занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на ленты, чему будет равна теоретическая эффективность при использовании 4 процессоров:
Каковы причины значительного снижения полезной вычислительной нагрузки для процессоров при организации волновых вычислений в системах с распределенной памятью?
В обобщенном алгоритме быстрой сортировки в дополнение к обычному методу быстрой сортировки предлагается:
Под процессом понимают:
Число итераций параллельного алгоритма Флойда равно:
Граф это:
Равновесность подмножеств вершин в задаче оптимального разделения графа:
Какие топологий сети не поддерживает система имитационного моделирования ПараЛаб:
Какие достоинства и недостатки имеет асинхронный механизм передачи сообщений?
Какая схема разделения данных используется при реализации параллельного алгоритма Гаусса?
Процессы, между которыми выполняется передача данных:
Какие достоинства имеет синхронный механизм передачи сообщений?
В рамках системы ПараЛаб какие присутствуют средства для детального изучения и исследования параллельных алгоритмов решения сложных вычислительных задач:
Пусть есть задача вычисления произведения всех элемента вектора . Пусть N = 10 и применяется каскадная схема, аналогичная схеме описанной в лекции для суммирования элементов вектора. Какая в этом случае минимально возможная высота дерева модели вычисления:
Для эффективного выполнения параллельного алгоритма умножения матрицы на вектор, основанного на блочном разделении матрицы, необходимо, чтобы процессоры вычислительной системы были объединены в топологию:
Какая из приведенных в лекции топологий (при одинаковом количестве процессоров) обладает наименьшим диаметром:
Ускорение параллельных вычислений – это:
При использовании метода передачи сообщений:
Циклический q-сдвиг, это операция, при которой:
Для организации параллельных вычислений в вычислительных системах с распределенной памятью необходимо:
Протяженность производного типа в MPI это:
Выбор способа разделения вычислений на независимые части основывается:
Этап распределения подзадач между процессорами является избыточным, если:
При выполнении параллельного алгоритма, основанного на ленточной схеме разделения данных, основной коммуникационной операцией является:
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 200x200. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать алгоритм Кеннона, чему будет равна теоретическая эффективность при использовании 4 процессоров:
С ростом числа процессоров, наибольшее ускорение демонстрирует:
Рассмотрим задачу поиска решения системы линейных уравнений. Размер матрицы системы линейных уравнений 10x10. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и в системе занимают w = 8 байт. Если при распараллеливании алгоритма Гауса использовалось 4 процессора, то какая в этом случае достигается теоретическая стоимость параллельного алгоритма:
Задача сортировки данных обычно формулируется как:
Базовая операция "сравнить и разделить" отличается от операции "сравнить и переставить":
При надлежащем выборе ведущих элементов в алгоритме быстрой сортировки исходный массив данных оказывается упорядоченным после выполнения:
Охватывающим деревом (или остовом) неориентированного графа называется:
При построении графических зависимостей для экспериментов, проведенных в режиме удаленного доступа к параллельной вычислительной системы, используется:
Для поддержки упорядоченности в ходе выполнения алгоритма обобщенной быстрой сортировки процессоры должны выполнять:
Стоимость вычислений - это:
Соседние вершины в нумерации кода Грея имеют:
При реализации параллельного алгоритма для метода сопряженных градиентов вычисления над векторами дублируются на всех процессорах для того, чтобы:
В чем состоят необходимые условия для возможности организации параллельных вычислений:
Модель вычислений – это:
Пусть в решаемой задаче последовательная часть составляет четыре единицы времени, а часть, допускающая линейное распараллеливание, шесть единицы времени. Если использовать закона Густавсона-Барсиса, сколько потребуется процессоров для достижения ускорения в два раза (результат округлите в большую сторону):
Длительность времени передачи одного слова данных по одному каналу передачи данных определяется:
Применение неблокирующего способа выполнения обменов позволяет:
Операцию редукции данных MPI_Reduce можно описать:
Разработка параллельных алгоритмов включает в себя этапы:
Управление распределением нагрузки для процессоров необходимо:
При выполнении параллельного алгоритма Гаусса основными коммуникационными операциями являются:
Параллельный вариант алгоритма Шелла состоит в следующем:
Задача разделения вычислительной сети, на которую разбивается область обрабатываемых данных, между процессорами может быть сведена:
Как исключается неоднозначность вычислений в параллельном алгоритме метода сеток на системах с общей памятью?
Пусть есть задача вычисления суммы следующего вида . Пусть N = 8 и применяется каскадная схема с минимально возможной высотой дерева модели вычисления. Чему в этом случае равна эффективность при использовании восьми вычислительных элементов:
В отличие от геометрических схем комбинаторные методы решения задачи оптимального разделения графов не принимают во внимание:
Трудоемкость параллельного алгоритма чет-нечетной сортировки оценивается выражением:
В декартовой топологии множество процессов представляется в виде:
Граф "процессы – каналы" используется:
Какие способы разделения элементов матрицы между процессорами вычислительной системы используются для разработки параллельных алгоритмов умножения матрицы на вектор?
Какая схема разделения данных используется при разработке параллельных алгоритмов Фокса и Кэннона?
Для эффективного выполнения алгоритма Кэннона необходимо, чтобы процессоры вычислительной системы были организованы в топологию:
При выполнении параллельного алгоритма, основанного на разделении данных на горизонтальные полосы, сбор данных полученных результатов выполняется при помощи:
Чем определяется эффективность параллельных вычислений?
К числу параметров вычислительной системы в системе ПараЛаб относятся:
Рассмотрим задачу поиска решения системы линейных уравнений. Пусть размер матрицы системы линейных уравнений 20x20. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип double и занимают w = 8 байт. Если при распараллеливании алгоритма сопряженных градиентов использовалось 4 процессора, то какая в этом случае достигается теоретическая стоимость параллельного алгоритма:
Среди предусмотренных в составе MPI операций передачи сообщений различают:
При вычислении общей суммы последовательности числовых значений стоимостно-оптимальным алгоритмом является:
Способы логического представления (отображения) топологий характеризуются следующими тремя основными характеристиками:
Все данные для передачи в качестве сообщения MPI описываются с помощью триады:
В буферизованном режиме функция отправки сообщения завершается:
Масштабирование разрабатываемого параллельного алгоритма это процесс:
Какие алгоритмы обладают наилучшими теоретическими показателями ускорения и эффективности (в случае, когда не учитываются затраты на передачу данных между процессорами):
При реализации параллельного алгоритма Гаусса рекомендуется использовать ленточную циклическую схему разделения данных, потому что
Для определения угла поворота в рекурсивном инерционном методе деления пополам при решении задачи оптимального разделения графов, используется:
При разработке параллельных алгоритмов решения дифференциальных уравнений в частных производных за основу выбирается разделение данных, потому что:
Рассмотрим задачу перемножения матрицы на вектор. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать разделение матрицы на строки чему будет равно теоретическая стоимость при использовании 2 процессоров:
Минимально охватывающим деревом называется:
Суперкомпьютеры:
Прием сообщений при помощи функции MPI_Recv может быть осуществлен:
Рассмотрим задачу перемножения матриц. Пусть размер перемножаемой матрицы 100x100. На вычислительной системе все операции сложения и умножения выполняются одинаковое время нсек. Латентности сети нсек. Пропускная способность сети Mбайт/сек. Элементы матрицы имеют тип double и занимают w = 8 байт. Если при распараллеливании использовать алгоритм Фокса, чему будет равно теоретическое ускорение при использовании 4 процессоров:
За счет чего увеличивается число передач данных между процессорами при блочном представлении сетки области расчетов на системах с распределенной памятью?
Среди рассмотренных в лекции типовых топологий приведены: