На электронную почту пришло два подозрительных письма, одно из них (A) содержало слово "лотерея", второе (B) – слова "лекарство" и "похудение". Дано, что спам составляет 3% писем, доля писем, где встречается слово "лотерея": спам - 0,04%, не спам – 0,01%; слово "лекарство": спам - 0,02%, не спам – 0,01%; слово "похудение": спам - 0,01%, не спам - 0,0005%. Пользуясь наивным байесовским классификатором (Naive Bayes) с правдоподобием Бернулли (BernoulliNB), определить, какие из полученных писем являются спамом.
Михаил получает на электронную почту в среднем 1000 писем в месяц, из них 2,44% - это спам. Известно, что среди спама слово "знакомство" встречается в 0,01% писем, а среди обычных писем в 10 раз реже. Какова вероятность того, что письмо, попавшее на почтовый ящик Михаила, в тексте которого встречается указанное слово, не является спамом? (Ответ укажите в целых процентах без знака процента.)
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8), при этом известно, что первый и третий примеры относятся к классу "1", а второй и четвертый – к классу "0". Для обучения на данных примерах применяется алгоритм случайный лес (random forest). Случайным образом были выбраны 5 наборов примеров и признаков: (1) пример 1 (признаки 1,2) + пример 2 (признаки 1,3); (2) пример 3 (признаки 2,3) + пример 4 (признак 1); (3) пример 2 (признаки 1,2,3) + пример 3 (признак 1); (4) пример 1 (признаки 1,3) + пример 2 (признак 1) + пример 3 (признак 3); (5) пример 1 (признаки 2,3) + пример 4 (признаки 2,3). Для этих пяти наборов были построены соответственно пять деревьев по алгоритму CART, нечистота (impurity) вычислялась по Джини. Принадлежность к классу определяется голосованием – числом деревьев, которые отнесли тот или иной пример к определенному классу. Сколько деревьев отнесут тестовый пример F(2;3;6) к классу "0"? (Напишите ответ в виде целого числа.)

Для чего используется логарифм правдоподобия Бернулли?
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8), при этом известно, что первый и третий примеры относятся к классу "1", а второй и четвертый – к классу "0". Проведите процедуру отбора признаков (feature selection) методом minimum redundancy maximum relevance (mRMR), используя логарифм по основанию 2. Укажите, какие признаки нужно оставить:
Дома на четной стороне улицы имеют номера 2, 4, 6, … . Номер дома – это признак:
В документе d слово "кластер" встречается с частотой TF("кластер",d)=0,0125. Мы имеем возможность программным образом изучить миллион документов, и выяснить, что указанное слово встречается только в 100 из них. Вычислите TF-IDF слова "кластер" в документе d с точностью до двух знаков после запятой:
Рассмотрим многослойный персептрон, состоящий из вытянутых в линейную цепочку 10 нейронов (один из них входной, один выходной, а 8 образуют 8 скрытых слоев). Для коррекции весов используется алгоритм обратного распространения ошибки (back propagation). Функция ошибки среднеквадратическая. Значения весов и ошибка на выходе не превышают по модулю единицы. Выберите, при каких значениях сигнала на входе градиент на входе может превысить 0,0001.
Принцип Maximum Likelihood
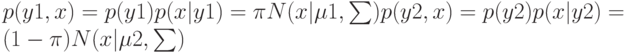
. Функция правдоподобия
![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png)
. Максимизируя

, в результате имеем одну из составляющих ?
Класс алгоритмов, являющийся элегантной идей по построению разделяющей поверхности, а также осуществляющий переход в новое пространство значительно дешевле, чем вычисление всех обучающие объектов в новом пространстве напрямую:
