Рассмотрим базу данных обработки заказов и создадим индексный кластер для хранения одной из таблиц базы данных - Customer.
CREATE CLUSTER cust_c (cust_id varchar(8))INDEX;CREATE INDEX cust_c_id ON CLUSTER cust_c;CREATE TABLE cust (cust_id varchar2(8) NOT NULL REFERENCES customers,ent# number NOT NULL,date_ent date NOT NULL,comment varchar2(60) NOT NULL,…PRIMARY KEY(cust_id, ent#)) CLUSTER cust_c (cust_id);
Созданная таблица кластеризована по колонке cust_id, и все специальные записи о клиента в колонке comment будут расположены в одной странице физической базы данных, либо в смежных страницах. Их можно выбрать за одну операцию поиска по индексу:
SELECT date_ent, comment FROM cust_c WHERE cust_id=:cur_cust;
Комментарий. Ограничение первичного ключа в операторе CREATE сделано, чтобы избежать создания второго индекса.
Является ли такое решение преимуществом с точки зрения утверждения: "Строки, имеющие специальные записи о клиенте, имеют более одной записи о клиенте".


 , где
, где 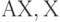 включает некоторый ключ.
включает некоторый ключ.