
Завершение функции MPI_Send означает, что:
(Отметьте один правильный вариант ответа.)
Варианты ответа
сообщение принято процессом-получателем при помощи функции MPI_Recv(Верный ответ)
сообщение находится в состоянии передачи
операция передачи начала выполняться и пересылка сообщения будет рано или поздно будет выполнена

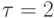 нсек. Латентности сети
нсек. Латентности сети 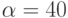 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип 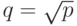 , где
, где 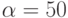 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип