Для чего используется логарифм правдоподобия Бернулли?
Что может служить мотивацией для снижения размерности пространства
Какие задачи может решать Text Mining
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8). В результате применения метода главных компонент исходное пространство признаков свели к двумерному пространству признаков на плоскости. Найдите евклидово расстояние между примерами C и D в редуцированном пространстве с точностью до одного знака после запятой:
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8). В результате применения метода главных компонент исходное пространство признаков свели к двумерному пространству признаков на плоскости. Какую часть общей дисперсии сохранило редуцированное пространство? Ответ укажите с точностью до трех знаков после запятой:
Сколько слоев может обработать одна ограниченная машина Больцмана (restricted Boltzmann machine - RBM)?
Имеются бактерии с двумя количественными признаками x1, x2, строится логистическая регрессия для определения вероятности, с которой бактерии относятся к одному из двух классов (видов) - y1 или y2. Предполагается нормальное распределение условных вероятностей, соответственно модель получается линейной, и p(y1|x)=1/(1+exp(-(w1*x1+w2*x2+w0))). В результате обучения были найдены следующие значения: w0=1, w1=3, w2=-4. Найдите, с какой вероятностью бактерия с признаками x1=1, x2=1 относится ко второму классу. Ответ укажите с точностью до одного знака после запятой:
Идея линейного классификатора определяется тем, что признаковое пространство может быть разделено гиперплоскостью на полупространства, в каждом из которых прогнозируется одно из двух значений целевого класса (линейная разделимость). Укажите число полупространств.
Принцип Maximum Likelihood
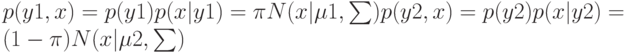
. Функция правдоподобия
![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png)
. Максимизируя

, в результате имеем одну из составляющих ?
Дан единичный квадрат с координатами вершин (0;0), (0;1), (1;1), (1;0). При этом первая и третья вершины относятся к классу "-1", а вторая и четвертая – "1". Требуется построить классификатор, получающий на входе координату вершины, а на выходе дающий метку класса (задача XOR). Функция потерь определяется числом неправильно классифицированных вершин с учетом их веса. В результате применения алгоритма AdaBoost были построены три модели со следующими разделяющими границами: (1) прямая, проходящая через точки (1/2;0) и (0;1/2), (2) прямая, проходящая через точки (1/2;1) и (1;1/2), (3) прямая, проходящая через точки (1/2;1) и (0;1/2). Изначально веса вершин одинаковы и равны 1/4, далее они пересчитываются в соответствии с алгоритмом. Укажите получившиеся веса первой, второй и третьей модели соответственно:

