
За основу организации параллельных вычислений при реализации метода сопряженных градиентов выбирается параллельное выполнение операции умножения матрицы на вектор, потому что:
(Ответ считается верным, если отмечены все правильные варианты ответов.)
Варианты ответа
операция умножения матрицы на вектор – наиболее трудоемкая из вычислительных операций итерации метода сопряженных градиентов(Верный ответ)
операция умножения матрицы на вектор может быть эффективно распараллелена (Верный ответ)
итерации метода сопряженных градиентов должны выполняться строго последовательно(Верный ответ)

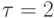 нсек. Латентности сети
нсек. Латентности сети 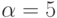 нсек. Пропускная способность сети
нсек. Пропускная способность сети 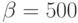 Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип
Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип 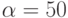 нсек. Пропускная способность сети
нсек. Пропускная способность сети  Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип
Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип  Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип
Mбайт/сек. Элементы матрицы системы линейных уравнений имеют тип