
Функция MPI_Recv:
(Отметьте один правильный вариант ответа.)
Варианты ответа
принимает сообщение в фоновом режиме, процесс в это время может продолжать вычисления
блокирует процесс-получатель до момента фактического получения сообщения(Верный ответ)
в зависимости от используемой операции передачи может, как заблокировать, так и не заблокировать процесс-получатель

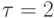 нсек. Латентности сети
нсек. Латентности сети 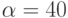 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип 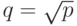 , где
, где 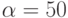 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип