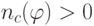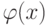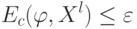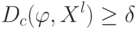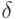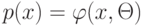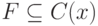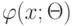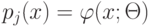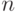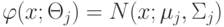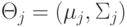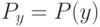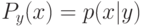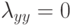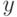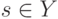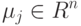Как будет называться закономерность 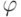 , если
, если  ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
непротиворечивой;(Верный ответ)
логической 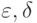 -закономерностью для класса
-закономерностью для класса 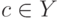 ;
;
частичной.