
Машинное обучение - ответы
Количество вопросов - 525
Действительно ли то, что ёмкость однопараметрического семейства может быть бесконечной?

Какие данные не используют в картах Кохонена в качестве входных?
Выберите правильный ответ. Задача ранжирования - это:
Верно ли утверждение. Наивный байесовский классификатор может быть как параметрическим, так и непараметрическим.
Как будет называться закономерность 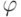 , если
, если 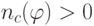 ?
?
Какой алгоритм позволяет найти пару вершин  с наименьшим
с наименьшим 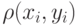 и соединить их ребром?
и соединить их ребром?
Как называется операция, отбирающая 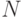 наиболее адаптивных индивидов популяции
наиболее адаптивных индивидов популяции  в алгоритме CCEL?
в алгоритме CCEL?
Какой пример, из ниже перечисленных, является примером смеси алгоритмов?
Выберите неверные утверждения:
Семейство линейных решающих правил будет выглядеть как:
Что, из ниже перечисленного, называется областью компетенции базового алгоритма 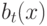 ?
?
Как называется величина 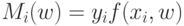 объекта
объекта 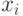 относительно алгоритма классификации
относительно алгоритма классификации 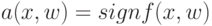 ?
?
Этап обучения - это:
Отступ показывает:
Какой алгоритм удаляет, те связи, к изменению которых функционал Q наименее чувствителен?
Чему соответствует прямоугольное ядро ![k(z)=\frac{1}{2}[|z|<1]](https://intuit.ru//sites/default/files/tex_cache/f4f55f4395bc8cc8b55d886fd5df7b45.png)
Чему способствует увеличение параметра  ?
?
Вероятность правильной классификации имеет вид:
Что называют эффективной размерностью задачи?
Как формула подходит для абсолютного значения ошибки для задач регрессии?
Что называют 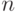 -мерным нормальным (гауссовским) распределением с вектором матожидания
-мерным нормальным (гауссовским) распределением с вектором матожидания 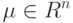 и ковариационной матрицей
и ковариационной матрицей  ?
?
Что означает запись  ?
?
Как называется основная процедура в алгоритме КОРА?
Правильнее и надежнее классификация объекта будет, если:
За что штрафует функция потерь 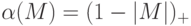 ?
?
Что означает 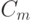 в правиле справедливой конкуренции CWTA?
в правиле справедливой конкуренции CWTA?
Что должно поступать на вход в алгоритме поочередного добавления и удаления?
По какой из формул вычисляются веса в областях локальных сгущений оптимальна меньшая ширина окна?
Что называют многослойной сетью?
Определите название данной задачи: имеется метод обучения 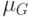 использующий только признаки из заданного набора признаков
использующий только признаки из заданного набора признаков  . Требуется найти набор признаков, при котором алгоритм
. Требуется найти набор признаков, при котором алгоритм  имеет наилучшую обобщающую способность.
имеет наилучшую обобщающую способность.
Объекты состоят из признаков?
Что является квадратичной ошибкой для задачи регрессии?
Если происходит средняя потеря на всех объектах, то это есть:
Верно ли следующее утверждение? Многие виды задач медицинской диагностики решаются задачами классификации.
Какие задачи, из ниже перечисленных, являются задачами прогнозирования?
Какие, из ниже перечисленных задач, являются задачами классификации?
Какой тип экспериментального исследования имеет цель - понимание, на что влияют параметры метода обучения?
Метод обучения - это:
Функционал среднего риска - это:
Если известны 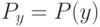 и
и 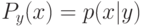 , то минимум среднего риска
, то минимум среднего риска  достигается при:
достигается при:
Формула восстановления смеси распределений может выглядеть как:
На какой из теории основан байесовский подход?
Общий вид равновероятных классов будет выглядеть:
Выберите правильный ответ. Эмперическая оценка среднего риска вычисляется по:
В формуле совместной плотности 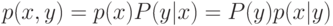 функцией априорной вероятности класса
функцией априорной вероятности класса 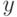 будет функция:
будет функция:
На локальной аппроксимации плотности 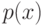 в окрестности классифицируемого объекта
в окрестности классифицируемого объекта  основано:
основано:
Что, из ниже перечисленного, относится к недостаткам квадратичного дискриминанта?
Верно ли, что если классы имеют нормальные функции правдоподобия, то байесовское решающее правило имеет квадратичную разделяющую поверхность.
Если при переобучении: на  всё хорошо, на
всё хорошо, на  всё плохо, то это проявление:
всё плохо, то это проявление:
Что применяют для проверки на равенство нулю элементов  ковариационной матрицы
ковариационной матрицы 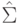 .
.
В какой из выборок является гистограммой значений для оценки плотности:
Если выполнены условия: 1) выборка 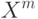 простая, получена из плотности распределения ; 2) ядро
простая, получена из плотности распределения ; 2) ядро 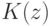 непрерывно, его квадрат ограничен:
непрерывно, его квадрат ограничен: 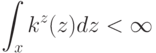 ; 3) последовательность
; 3) последовательность  такова, что
такова, что 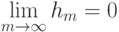 и
и  , тогда:
, тогда:
Верно ли утверждение. Функции правдоподобия принадлежат параметрическому семейству распределений 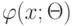 и отличаются только значениями параметра
и отличаются только значениями параметра 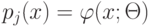 .
.
Выберите верные утверждения:
Константы смеси имеют -мерные нормальные распределения 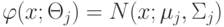 с параметрами
с параметрами 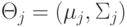 , где
, где  - это:
- это:
Весовой функцией является функция:
Какой алгоритм относит классифицируемый объект  к тому классу, которому принадлежит обучающий объект?
к тому классу, которому принадлежит обучающий объект?
К какому алгоритму можно отнести формулу: ![w(i,u)=[i=1]; a(u;X^l)=y_u^{(1)}](https://intuit.ru//sites/default/files/tex_cache/2d1a5e80464675d1fa2f5874664f54b7.png) ?
?
Какой получится алгоритм, если ввести функцию ядра 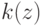 невозрастающую на
невозрастающую на 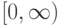 и положив
и положив  в формуле
в формуле  ?
?
Какие, ниже перечисленные, недостатки можно отнести к метрическим алгоритмам 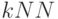 ?
?
Отступом (margin) объекта 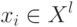 относительно алгоритма классификации, имеющего вид
относительно алгоритма классификации, имеющего вид 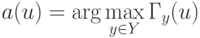 называется величина:
называется величина:
Большой положительный отступ, плотно окруженный объектами своего класса имеют:
Как называется функция 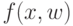 ?
?
Пусть есть задача с 2-мя классами 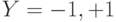 . К какому классу будет относится алгоритм, если
. К какому классу будет относится алгоритм, если  ?
?
Правильнее и надежнее классификация объекта будет, если:
Какая, из перечисленных ниже функций, соответствует методу опорных векторов?
Для чего вводится параметрическое семейство априорных распределений 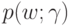 ?
?
Что, из ниже перечисленного, относится к недостаткам метода SG?
Какой вид будет иметь правило обновления весов на каждой итерации метода стохастического градиента?
Какая функция, из ниже перечисленных, является функцией активации?
Как называется функция ?
Пусть есть задача с 2-мя классами . К какому классу будет относится алгоритм, если  ?
?
Будет ли алгоритм допускать ошибку на объекте , если 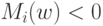 ?
?
Какая, из перечисленных ниже функций, соответствует линейному дискриминанту Фишера?
Для чего вводится параметрическое семейство априорных распределений ?
Что, из ниже перечисленного, относится к недостаткам метода SG?
Какой вид будет иметь правило обновления весов на каждой итерации метода стохастического градиента?
Какая функция, из ниже перечисленных, является функцией активации?
Действительно ли что, ширина полосы минимальна, когда норма вектора w минимальна?
Что следует из формулы  ?
?
Какие объекты называются опорными?
Если объекты либо лежат внутри разделяющей полосы, но классифицируются правильно 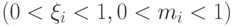 , либо попадают на границу классов
, либо попадают на границу классов 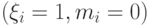 , либо вообще относятся к чужому классу
, либо вообще относятся к чужому классу 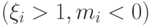 , то их называют:
, то их называют:
Действительно ли, что построение адекватного ядра является искусством и, как правило, опирается на априорные знания о предметной области?
Что, из ниже перечисленного, не является входными данными в последовательном методе активных ограничений?
Выберите верное утверждение.
Какая функция не считает за ошибки отклонения 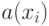 от
от  , меньшие
, меньшие  ?
?
Какая функция позволяет говорить о "близости" объектов, на множестве 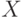 ?
?
На что влияет выбор ядра K?
При каком размере окна h функция чрезмерно сглаживается?
Формула скользящего контроля с исключением объектов по одному выглядит:
Как называются методы восстановления регрессии, устойчивые к шуму в исходных данных?
Что будет являтся решением нормальной системы?
Что надо добавить для решения проблемы мультиколлинеарности?
Как выглядит гессиан функционала Q в точке 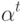 ?
?
В какой из формул указан итерационный процесс уточнения вектора коэффициентов 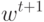 ?
?
Что представляет собой матрица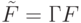 ?
?
Что получают на выходе в алгоритме IRLS?
Набор функций 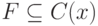 будет называться замкнутым относительно функции
будет называться замкнутым относительно функции  , если:
, если:
Как называется метод, который позволял вычислять градиент, при котором каждый градиентный шаг выполняется за число операций, лишь немногим больше, чем при обычном вычислении сети на одном объекте?
Верно ли что, если обучающая выборка имеет большой объем, то можно использовать метод Хебба?
Процесс упрощения сети, в алгоритме OBD, останавливается, когда:
Что, из ниже перечисленного, не относится к целям кластеризации?
Какую функцию невозможно реализовать одним нейроном с 2-мя входами 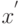 и
и  ?
?
Какие слои в нейронной сети называются скрытыми?
Что такое 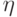 в формуле:
в формуле: ![w_m:=w_m + \eta(x_i - w_m)[a(x_i) = m]](https://intuit.ru//sites/default/files/tex_cache/da86b4a213058b68c1dfd78065a42803.png) ?
?
Что называют нейронами Кохонена?
Какое правило означает следующая формула 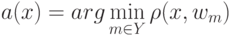 ?
?
Самоорганизующиеся карты Кохонена применяются для:
Как выглядет формула стресса в задаче многомерного шкалирования?
Верно ли, что при n=3 многомерное шкалирование позволяет отобразить выборку в виде множества точек на плоскости?
От чего зависит функционал стресса 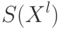 ?
?
Верно ли, что при частичном обучении можно получить метки  зная все ?
зная все ?
Какой алгоритм является self-traning для композиции простого голосования базовых алгоритмов  ?
?
Какая из формул позволит решить задачу с помощью алгоритма co-learning?
Какой алгоритм имеет процедуру удаления k-1 самых длинных ребер?
К какому алгоритму относится недостаток неустойчивого решения, если нет области разреженности?
Верно ли, что оценить вероятность 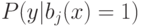 можно, только с помощью эмпирической оценкой по различным данным?
можно, только с помощью эмпирической оценкой по различным данным?
Оценка расстояний между двумя распределениями с помощью дивергенции Кульбака-Лейблера будет выглядеть:
Как называется функция  в алгоритмах имеющих вид суперпозиции
в алгоритмах имеющих вид суперпозиции 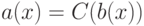 ?
?
Как называется алгоритм 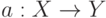 вида
вида 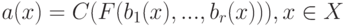 ?
?
Что из ниже перечисленного относится к корректирующим операциям?
Какой пример, из ниже перечисленных, является примером простого голосования?
Если в корректирующей операции 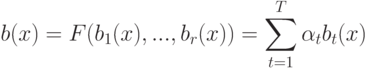 , параметры
, параметры 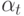 неотрицательны и нормированы,
неотрицательны и нормированы,  , то композиция называется:
, то композиция называется:
Чему эквивалентна минимизация функционала 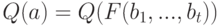 по базовому алгоритму
по базовому алгоритму 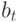 ?
?
Что не способствует уменьшению параметра ?
Что из ниже перечисленного относится к недостаткам алгоритма AdaBoost?
Какой алгоритм предпочтительней, когда признаков больше, чем объектов?
Какие параметры участвуют в алгоритмической композиции CCEL?
В каком методе из исходной обучающей выборки длины l формируются различные обучающие подвыборки той же длины l с помощью случайного выбора с возвращениями?
Сколько популяций строится на t-м поколении алгоритма CCEL?
Что такое селекция 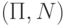 в методе CCEL?
в методе CCEL?
Действительно ли, что беггинг работает лучше на больших обучающих выборках?
Какие параметры используются в алгоритме последовательного построения смеси?
Как определяется индикатор ошибки в задачах обучения по прецедентам?
Что называют частотой ошибок алгоритма a на произвольной подвыборке  ?
?
Как определить функционал в качестве вероятности частоты ошибок на контроле превышающее заданное число ![\epsilon \in [0,1]](https://intuit.ru//sites/default/files/tex_cache/f6182f4faa86606fd4be7797ed74a7f5.png) ?
?
Как будет выглядеть формула вероятности ошибки в интерпретации обобщающей способности метода 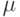 ?
?
Алгоритмы  и
и 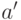 неразличимы на выборке , если:
неразличимы на выборке , если:
Верно ли, что функция роста не зависит ни от выборки, ни от метода обучения?
Верно ли утверждение, что ёмкость семейства линейных решающих правил А равна размерности пространства n?
Что называют выбором структуры модели?
Что называют моделью алгоритмов?
Определите название данной задачи: имеется конечное множество альтернативных моделей 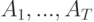 , каждая со своим методом обучения,
, каждая со своим методом обучения, 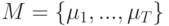 . Требуется найти модель, наиболее адекватную для данной выборки.
. Требуется найти модель, наиболее адекватную для данной выборки.
Функционал 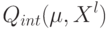 , характеризующий качество метода по обучающей выборке называют:
, характеризующий качество метода по обучающей выборке называют:
Как называется функционал  ?
?
Как называется критерий 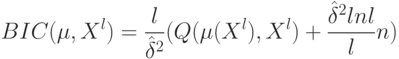 ?
?
Выберите правильную характеристику для внешнего критерия.
Что должно поступать на вход в алгоритме полного перебора?
Как называется алгоритм, который осуществляет полный перебор всевозможных наборов признаков G в порядке возрастания сложности?
Как будет называться предикат 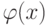 , если
, если 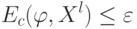 и
и 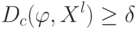 при заданных достаточно малом и достаточно большом
при заданных достаточно малом и достаточно большом 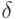 из отрезка [0,1]?
из отрезка [0,1]?
Что, из ниже перечисленного характеризует энтропийное определение информативности?
Что, из ниже перечисленного характеризует взвешенную информативность?
Какая формула характерна, если  представляет количественный признак?
представляет количественный признак?
Что называют рангом в форме конъюнкций?
Какие данные подаются на вход "градиентного" алгоритма синтеза конъюнкции?
Какой алгоритм использует только операцию добавления термов?
По какой из формул параметрическое семейство Ф можно отнести к параметрическому семейству шаров?
Какой входной набор данных характерен для жадного алгоритма построения решающего списка?
К чему приводит уменьшение параметра  при оптимизации сложности решающего списка?
при оптимизации сложности решающего списка?
Что такое бинарное решающее дерево?
Что является выходными данными в алгоритме синтеза бинарного решающего дерева 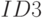 ?
?
Что, из ниже перечисленного характерно для предредукции?
Какой алгоритм строит набор конъюнктивных закономерностей?
Что, из ниже перечисленного является достоинством алгоритма КОРА?
При каком условии множество  будет называться тестом?
будет называться тестом?
Выберите верный вариант. Если для каждого класса 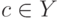 построено множество логических правил, специализирующихся на различении объектов данного класса
построено множество логических правил, специализирующихся на различении объектов данного класса 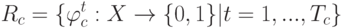 и если
и если 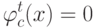 , то:
, то:
Выберите правило, при голосовании которым берётся взвешенная сумма голосов?
Что делает конъюнкция в алгоритме КОРА, если она выделяет слишком мало объектов своего класса?
Что из ниже перечисленного не относится к задачам коллаборативной фильтрации?
В какой модели по данным 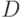 оцениваются векторы: профили клиентов и профили объектов?
оцениваются векторы: профили клиентов и профили объектов?
Что является основой латентного семантического анализа?
Какие данные в качестве входных применяются в алгоритме двухступенчатой симметризации?
Что из ниже перечисленного не относится к моделям основанным на хранении исходных данных?
Что является недостатком модели от клиента?
Что из ниже перечисленного не является типом латентной модели?
Что из ниже перечисленного является функционалом качества кластеризации?
Что из ниже перечисленного не относится к вероятностной модели коллекции документов?
Что означает запись  ?
?
Какая запись соответствует числу троек, связанных с темой t?
Какое обозначение соответствует задаче приближенного представления заданной матрицы частот?
Как будет называться модель, в которой учитывается 11 слов?
Приведение каждого слова в документе к его нормальной форме называется:
Что является элементами кластеров?
Какая компонента, из ниже перечисленных, является шумовой компонентой?
Как называют априорную вероятность вида: 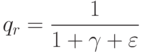 ?
?
Что из ниже перечисленного не определяет метаинформацию?
Что характеризует гипотеза условной независимости вида: 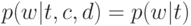 ?
?
Какие модели, из ниже перечисленных относятся к динамическим тематическим моделям?
Что называют обучением с подкреплением?
Как называется метод, который использует жадные действия большую часть времени?
Какое соотношение позволяет реализовать идею, согласно которой высокие вознаграждения должны увеличивать вероятность повторного выбора предпринятого действия?
Что называется вероятностями перехода?
Какую функцию называют функцией ценности состояния для стратегии 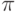 ?
?
Какой метод усредняет выгоды, соответствующие только первым посещениям s?
Какая форма будет называться Q-обучением?
Какая идея, из ниже перечисленных, описывает метод 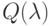 Уоткинса?
Уоткинса?
Что будет градиентным шагом в формуле ?
Каким способом можно получить гребневую регрессию?
Выберите, что подходит под определение коэффициента разнообразия 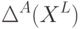 множества алгоритмов А на выборке
множества алгоритмов А на выборке 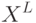 ?
?
Какая оценка справедлива для функции роста, если множество А конечно, а число алгоритмов, попарно неразличимы на выборке ?
Чему соответствует точечное ядро ![k(z)=[z=0]](https://intuit.ru//sites/default/files/tex_cache/fe7e5eed6dff0327f0a1f35d60ccef70.png) при единичной ширине окна
при единичной ширине окна 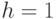 :
:
Выберите правильный ответ. Задача классификации - это:
Что из ниже перечисленного представления описывает процесс порождения коллекции D?
Есть гипотеза, где классы имеют -мерные гауссовские плотности: 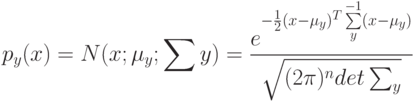 , где -
, где -  , то вектором матожидания класса будет:
, то вектором матожидания класса будет:
Выберите верные утверждения.
Как будет называться закономерность , если  ?
?
Эмпирической оценкой плотности является функция:
Что из ниже перечисленного является типом латентной модели?
Какая из формул позволит решить задачу частичного обучения?
Верно ли, что при n=1 многомерное шкалирование позволяет отобразить выборку в виде множества точек на плоскости?
В задачах классификации признаки могут быть строковыми, вещественными, числовыми.
В зависимости от значений отступа обучающие объекты условно делятся на:
Что, из ниже перечисленного является достоинством алгоритма ТЭМП?
Какое выражение, из перечисленных ниже, называется байесовским решающим правилом:
Какой получится алгоритм, если  определить как наибольшее число, при котором ровно
определить как наибольшее число, при котором ровно 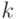 ближайших соседей объекта
ближайших соседей объекта  получают нулевые веса:
получают нулевые веса: 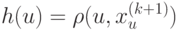 .
.
Локальную аппроксимацию выборки строит алгоритм:
Какой метод оценивает 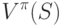 как среднее значение выгод, соответствующих всем посещениям s в некоторой совокупности эпизодов?
как среднее значение выгод, соответствующих всем посещениям s в некоторой совокупности эпизодов?
Как будет выглядеть формула вероятности, когда переобученность превышает допустимый порог 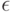 ?
?
Если функция 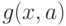 достаточное число раз дифференцируема по
достаточное число раз дифференцируема по  , то:
, то:
Что, из ниже перечисленного характерно для постредукции?
Что, из ниже перечисленного, не подается на вход в алгоритме IRLS?
Что из ниже перечисленного не является элементом обучения с подкреплением?
Какая форма является TD-ошибкой?
За что штрафует функция ?
Какие пространства признаков называются спрямляющими?
Действительно ли, что метод INCAS позволяет решать задачи, в которых нет линейной разделимости?
Какой алгоритм имеет такое условие, что пока есть путь между двумя вершинами разных классов, то удалить самое длинное ребро на этом пути?
Верно ли, что трансдуктивное обучение - это построение алгоритма классификации ?
К какому алгоритму относится недостаток настройки двух параметров 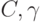 ?
?
Что называют данными в машинном обучении?
Что служит индикатором ошибки для задач классификации?
Эмпирический риск - это средняя потеря на одном объекте.
Какие задачи из ниже перечисленных относятся к задачам классификации?
Что, из ниже перечисленного, не относится к типу экспериментального исследования?
Апостеорной вероятностью класса для объекта 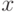 называется:
называется:
Формула параметрического оценивания плотности может выглядеть как:
Если байесовское решающее правило написать через апостериорные вероятности, то получится формула вида:
В формуле совместной плотности функцией правдоподобия класса будет функция:
Выберите неверные утверждения:
Если матрица близка к вырожденной, то это называется:
Идея EM-алгоритма с последовательным длбавлением компоненты заключается в следующем:
Константы смеси имеют -мерные нормальные распределения с параметрами , где 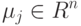 - это:
- это:
Выберите какие недостатки относятся не к алгоритму ближайшего соседа?
К какому алгоритму можно отнести формулу: ![w(i,u) = [i \le k]w_i; a(u;X^l,k) = \arg \max_{y \in Y}\sum_{i=1}^k [y_{(n)}^{(i)} = y]](https://intuit.ru//sites/default/files/tex_cache/f5fddb5dc5e005733b611f4d0cef6486.png) ?
?
Отрицательные отступы и классифицирующиеся неверно имеют:
Что будет называться в параметрическом семействе отображений: 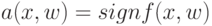 , вектором параметров?
, вектором параметров?
Будет ли алгоритм допускать ошибку на объекте , если ?
Какая, из перечисленных ниже функций, соответствует алгоритму бустинга Ada Boost?
Какой эвристический приём характеризует нормализацию признаков?
Что будет называться в параметрическом семействе отображений: , вектором параметров?
Пусть есть задача с 2-мя классами . К какому классу будет относится алгоритм, если 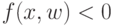 ?
?
Какая, из перечисленных ниже функций, соответствует алгоритму бустинга Ada Boost?
В формуле 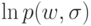 , что будет выступать в роли гиперпараметра?
, что будет выступать в роли гиперпараметра?
Что получится, если дискриминантная функция определяется как скалярное произведение вектора и вектора параметров 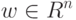 ?
?
Какое условие называют условием дополняющей нежёсткости?
Объекты называются периферийными?
Если объекты классифицируется правильно и находятся далеко от разделяющей полосы, то их называют:
В чем преимущества SVM перед метдом стохастического градиента?
Что, из ниже перечисленного, является входными данными в последовательном методе активных ограничений?
При каком размере окна h функция в пределе 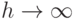 вырождается в константу?
вырождается в константу?
Вычисление оценки скользящего контроля на каждом объекте выглядит следующим образом:
Каким способом можно уменьшить норму вектора коэффициентов?
Как будет выглядеть градиент функционала Q в точке ?
Выражение для градиента будет выглядеть:
Функция F будет называться разделяющими точками множества X, если:
Какие будут входные данные, если сеть обучать методом обратного распространения ошибки?
Верно ли что, если обучающая выборка имеет большой объем или если решается задача классификации, то можно использовать метод стохастического градиента с адаптивным шагом?
Что означает, если веса 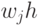 между входными и скрытым слоем будут обнулены?
между входными и скрытым слоем будут обнулены?
Как называют выражение 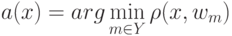 ?
?
Какой нейрон называют нейроном-победителем?
Какое правило означает следующая формула  ?
?
Какие входные данные нужны для карт Кохонена?
Формула гладкой аппроксимации имеет вид:
Верно ли, что при n=2 многомерное шкалирование позволяет отобразить выборку в виде множества точек на плоскости?
Верно ли, что частичное обучение - это построение алгоритма классификации ?
Степень доверия классификации 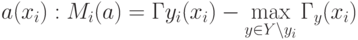 называется:
называется:
За что штрафует функция 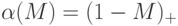 ?
?
Действительно ли, что метод XR слабо чувствителен к выбору ?
С помощью какой формулы можно оценить вероятность 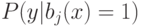 по размеченным данным ?
по размеченным данным ?
Оценка расстояний между двумя распределениями с помощью расстояния Хелингера будет выглядеть:
В каком алгоритме встречается алгоритмический оператор ?
Как называются операторы при фиксированном решающем правиле?
К какому классу отнесет объект решающее правило С: 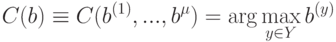 ?
?
Как называют произведения  в смесях алгоритмов?
в смесях алгоритмов?
Что объясняет эффективность бустинга?
Какие алгоритмы лучше работают на больших обучающих выборках?
Какие параметры участвуют в алгоритме RSM?
В каком методе базовые алгоритмы обучаются на различных подмножествах признакового описания, которые выделяются случайным образом?
Что такое рекомбинация  в методе CCEL?
в методе CCEL?
К любым ли базовым алгоритмам и их методам обучения применим алгоритм CCEL?
Что, из ниже перечисленного называют компонентами смеси?
Что будет на выходе в алгоритме M2E?
Что называют разностью 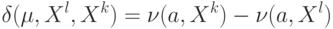 ?
?
Как определяется функционал полного скользящего контроля?
Что называют синтезом признаков?
Какой метод строит алгоритм, доставляющий минимальное значение внутреннему критерию: 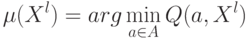 ?
?
Как называется критерий:  ?
?
Как называется критерий  ?
?
Как называется алгоритм, который добавляет к набору G по одному признаку, каждый раз выбирая тот признак, который приводит к наибольшему уменьшению внешнего критерия?
Что, из ниже перечисленного характеризует энтропийный критерий?
Какая формула характерна, если представляет порядковый признак?
Что называют зонами значений признака ?
Какие данные подаются на вход жадного алгоритма слияния зон?
По какой из формул параметрическое семейство Ф можно отнести к параметрическому семейству областей?
Что, из ниже перечисленного является недостатком решающих списков?
Что такое решающий список?
Какой алгоритм подсчитывает долю правил в наборах 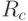 , относящих объект к каждому из классов?
, относящих объект к каждому из классов?
При каком условии представительный набор 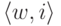 называется тупиковым?
называется тупиковым?
Определите какая из формул не участвует ни в простом ни взвешенном голосовании:
Задача выявления содержательно интерпретируемых латентных характеристик клиентов и ресурсов относится к задаче коллаборативной фильтрации?
Как называется вектор условных вероятностей 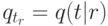 , если данный ресурс
, если данный ресурс  соответствует теме
соответствует теме 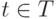 ?
?
Что является основой анамнестических алгоритмов?
Что из ниже перечисленного не относится к латентной модели?
Являются ли вероятностные модели типом латентных моделей?
Что из ниже перечисленного является Е-шагом ЕМ-алгоритма?
Что означает запись  ?
?
Какая запись соответствует числу троек, в которых термин w связан с темой t?
Какое обозначение соответствует матрице тем документов  ?
?
Как будет называться модель, в которой учитывается пара слов?
Что определяет векторный параметр ?
Какая компонента, из ниже перечисленных, является файловой компонентой?
Какие модели, из ниже перечисленных относятся к многоязычным тематическим моделям?
Какие элементы, из ниже перечисленных относятся к обучению с подкреплением?
Как называется метод, который применяют для оценивания ценности?
Что называют финитным марковским процессом принятия решений?
Какую величину называют относительной ценностью?
Какая идея, из ниже перечисленных, описывает идею алгоритма 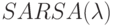 ?
?
Что показывает величина  ?
?
Чему способствует уменьшение параметра ?
Какой входной набор данных является лишним для жадного алгоритма построения решающего списка?
Что называют в теории нейронных сетей сокращением весов?
Идея алгоритма EM заключается в следующем:
Радиальными функциями принято называть функции:
Верно ли, что по мере увеличения сложности модели 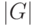 внутренний критерий возрастает?
внутренний критерий возрастает?
Какой алгоритм представляет функцию , которая любому объекту ставит в соответствие метку кластера ?
Что такое мутация (П) в методе CCEL?
Как называется функция вида:  ?
?
Этап тестирования - это:
Оценка расстояния между двух распределений с помощью статистики 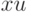 - квадрат будет выглядеть:
- квадрат будет выглядеть:
Что получается на выходе в алгоритме жадного построения решающего списка?
Разделяющая поверхность 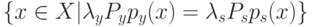 квадратичная для всех ,
квадратичная для всех , 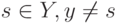 будет вырождена в линейную, если:
будет вырождена в линейную, если:
Какой алгоритм на каждом шаге отбирает целые популяции?
По какой формуле определяется энтропия?
Выберите верный вариант. Если для каждого класса построено множество логических правил, специализирующихся на различении объектов данного класса и если 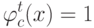 , то:
, то:
Если в корректирующей операции  функция
функция 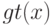 принимает только два значения
принимает только два значения 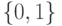 , то множество всех , для которых
, то множество всех , для которых 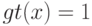 , называется:
, называется:
Величина потери от ошибки - это:
Что поступает на вход рекурсивного алгоритма синтеза бинарного решающего дерева ?
Какие ценности действий называют методами Монте-Карло?
Что, из ниже перечисленного, относится к обучающей выборке?
Верно ли утверждение? Всякая оптимизация по неполной информации и избыточная сложность параметров приводит в переобучению.
Какая, из ниже перечисленных задач, является задачей классификации на 4 класса?
Если известны и , и 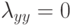 , а
, а  для всех ,
для всех , 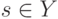 , то минимум среднего риска достигается при:
, то минимум среднего риска достигается при:
Какие, из ниже перечисленных подходов, относятся к подходам оцениванию:
Выберите правильный ответ. По контрольной выборке вычисляется:
В формуле совместной плотности функцией апостеорной вероятности класса будет функция:
Если нормаль разделяет гиперплоскость 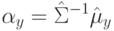 неустойчива, то это проявление:
неустойчива, то это проявление:
Чтобы использовать расстояние Махаланобиса в задаче определения принадлежности заданной точки одному из классов, нужно найти матрицы ковариации всех классов.
Если объекты описываются числовыми признаками 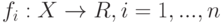 , тогда:
, тогда:
Плотность распределения на имеет вид смеси распределений 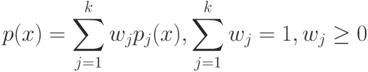 , где
, где 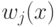 - это:
- это:
Выберите, какие недостатки относятся к алгоритму ближайшего соседа?
Как называется параметр в формуле ![a(u; X^l,h) = \arg \max_{y \in Y} \sum_{i=1}^l[y_n^{(i)}=y] k(\frac{\rho(u,x_u^{(i)})}{h})](https://intuit.ru//sites/default/files/tex_cache/51a55dbfe7e526a8e5547f4ca8ac785d.png) ?
?
Какие преимущества, из ниже перечисленных, относятся к преимуществам метода SG?
Что называют в теории нейронных сетей сокращением весов?
Что получится, если дискриминантная функция определяется как скалярное произведение вектора и вектора параметров ?
С чем, из ниже перечисленного сравнивают линейный классификатор?
Какая, из перечисленных ниже функций, соответствует методу опорных векторов?
Какая величина называется гиперпараметром?
Действительно ли что, ширина полосы максимальна, когда норма вектора w максимальна?
Какие объекты не являются опорными?
В ядре  , параметр - называется:
, параметр - называется:
Что будет называться псевдообратной для прямоугольной матрицы F?
Выражение для гессиана будет выглядеть:
Что подается на вход в алгоритме IRLS?
Какая сеть будет называться полносвязной?
Что означает обнуление веса 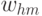 между скрытым и входным слоями?
между скрытым и входным слоями?
Дробление крупных кластеров на более мелкие называется задачей:
С помощью какой формулы решается задача исключающего ИЛИ?
Каким способом можно избавиться от неинформативного пустого кластера?
С помощью какого правила можно построить гладкую аппроксимацию?
Какая из формул позволит решить задачу кластеризации?
Как называется функция 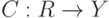 в алгоритмах имеющих вид суперпозиции ?
в алгоритмах имеющих вид суперпозиции ?
Что из ниже перечисленного не относится к корректирующим операциям?
Какой пример, из ниже перечисленных, является примером взвешенного голосования?
Какой алгоритм позволяет получить на выходе алгоритмическую композицию 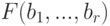 ?
?
Что из ниже перечисленного является достоинством алгоритма AdaBoost?
Какие алгоритмы лучше работают на коротких обучающих выборках?
Какая функция, из ниже перечисленных, представляет собой квазилинейную корректирующую операцию?
Что получается на выходе при построении 2-х базовых алгоритмов?
Что называют методом обучения?
Определите название данной задачи: имеется одна модель А, и один метод обучения 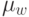 с параметром
с параметром  , который не может быть настроен по обучающей выборке. Требуется подобрать наиболее подходящие значения гиперпараметра.
, который не может быть настроен по обучающей выборке. Требуется подобрать наиболее подходящие значения гиперпараметра.
Как называется критерий, который характеризует качество метода по тем данным, которые не использовались в процессе обучения?
Выберите правильную характеристику для внутреннего критерия.
Как называется алгоритм, который последовательно удаляет избыточные признаки?
Что, из ниже перечисленного характеризует эффективное вычисление информативности с применением формулы Стирлинга?
Выберите верное утверждение:
Что не является входными данными в алгоритме синтеза бинарного решающего дерева ?
Что из ниже перечисленного относится к задачам коллаборативной фильтрации?
Какие данные не являются входными в алгоритме двухступенчатой симметризации?
Что из ниже перечисленного представления называется гипотезой условной независимости?
Какая запись соответствует числу троек, в которых термин документа d связан с темой t?
Какое обозначение соответствует матрице терминов тем Ф?
Отбрасывание изменяемых частей слов, главным образом, окончаний называется:
Какая компонента, из ниже перечисленных, является тематической компонентой?
Как называют априорную вероятность вида: 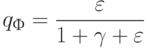 ?
?
Что, из ниже перечисленного называют метаинформацией?
Какие модели, из ниже перечисленных относятся к многомодальным тематическим моделям?
Как называется метод, который варьирует вероятность действий, представляемых посредством некоторой функции от предполагаемых значений ценности?
Верно ли, что метод не принимает в расчет все будущие ситуации вплоть до конца эпизода при выполнении дублирования?
Пусть есть задача с 2-мя классами . К какому классу будет относится алгоритм, если ?
Что из ниже перечисленного относится к моделям основанным на хранении исходных данных?
Что называют методом обучения?
Какую функцию называют функцией ценности действия для стратегии ?
Верно ли утверждение? Метод SG позволяет настраивать веса на избыточно больших выборках, за счет того, что случайной подвыборки может оказаться достаточно для обучения.
Какой тип экспериментального исследования имеет цель - либо решение конкретной прикладной задачи, либо выявление «слабых мест»?
Что, из ниже перечисленного, является функцией активации?
В чем недостатки SVN?
Какие задачи, из ниже перечисленных, являются задачами ранжирования?
Какой пример подходит для задачи восстановления регрессии?
На предположении, что плотность распределения известна с точностью до параметра, 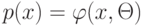 , где - фиксированная функция, основано:
, где - фиксированная функция, основано:
Есть гипотеза, где классы имеют -мерные гауссовские плотности: , где - , то ковариационной матрицей класса будет:
К какому алгоритму можно отнести формулу: ![w(i,u) = [i \le k]w_i; a(u;X^l,k) = \arg \max_{y \in Y}\sum_{i=1}^k [y_{(n)}^{(i)} = y]w_i](https://intuit.ru//sites/default/files/tex_cache/f396fd7e432131bac7932db94f3cdbb6.png) ?
?
Что, из нижк перечисленного, можно назвать достоинством метода потенциальных функций?
Пусть есть задача с 2-мя классами . К какому классу будет относится алгоритм, если ?
Какие преимущества, из ниже перечисленных, относятся к преимуществам метода SG?
Какой эвристический приём характеризует нормализацию признаков?
Действительно ли что, ширина полосы максимальна, когда норма вектора w минимальна?
Какое условие называют опорным вектором?
Какие объекты называются нарушителем?
Выберите противоречивое утверждение.
Какие объекты являются опорными?
Что называют задачей восстановления регрессии?
Следующая формула 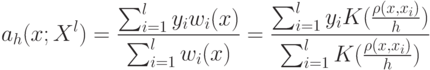 , называется:
, называется:
При каком размере окна h функция 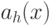 стремится пройти через все точки выборки?
стремится пройти через все точки выборки?
Если используется квартическое ядро  , где
, где 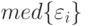 - медиана вариационного ряда ошибок, то это называют:
- медиана вариационного ряда ошибок, то это называют:
Что называют линейной комбинацией признаков с коэффициентами 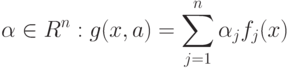 ?
?
Верно ли, что любая непрерывная функция n аргументов на единичном кубе ![[0,1]^n](https://intuit.ru//sites/default/files/tex_cache/0dca0690a28084bef5b302e338fa1468.png) представлена в виде суперпозиции непрерывных функций одного аргумента и операции сложения:
представлена в виде суперпозиции непрерывных функций одного аргумента и операции сложения: 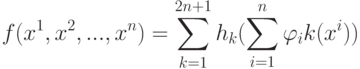 ?
?
Когда появляется неинформативный пустой кластер при конкурентном обучении по правилу WTA?
Каким способом можно избавиться от медленной скорости сходимости в правиле WTA?
С помощью какой формулы можно оценить вероятность по неразмеченным данным и линейной модели?
Чтобы оценить качество алгоритмических операторов 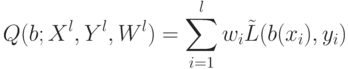 надо:
надо:
Какие параметры участвуют в алгоритме Беггинга?
Действительно ли, что RSM выполняется строго последовательно не допуская эффективного распространения?
Как будет выглядеть формула вероятности ошибки в интерпретации обобщающей способности метода , если взять матожидание по выборке от функционала 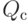 ?
?
Если алгоритмы a и a' допускают ошибки на одних и тех же объектах, то их называют:
Что называется переобучением?
Что называют выбором метода?
Какой алгоритм пытается улучшить конъюнкцию , удаляя или заменяя по одному терму?
Какой алгоритм каждому правилу 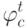 приписывает вес
приписывает вес  , и при голосовании берётся взвешенная сумма голосов
, и при голосовании берётся взвешенная сумма голосов  ?
?
При каком условии совокупность будет называться представительным набором?
На что, из ниже перечисленного, влияют параметры  и ?
и ?
Какие данные являются выходными в алгоритме двухступенчатой симметризации?
Что из ниже перечисленного не относится к недостаткам тривиальной рекомендующей системой?
Как будет называться модель, в которой учитывается тройка слов?
Как называют априорную вероятность вида: 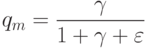 ?
?
Относится ли список ярлыков 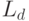 , присвоенных пользователями документу d к метаинформации?
, присвоенных пользователями документу d к метаинформации?
Что характеризует гипотеза условной независимости вида: 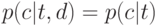 ?
?
С какой вероятностью осуществляется выбор действия в t-й игре?
Предположим, что требуется оценить величину 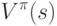 , имея набор эпизодов, полученных при применении стратегии и прохождении через состояние s. Как тогда будет называться каждое появление состояния s в эпизоде?
, имея набор эпизодов, полученных при применении стратегии и прохождении через состояние s. Как тогда будет называться каждое появление состояния s в эпизоде?
Верно ли утверждение? Метод SG позволяет настраивать веса на избыточно больших выборках, за счет того, что случайной подвыборки может оказаться достаточно для обучения.
Что называют марковским процессом принятия решений?
Какая формула характерна, если представляет номинальный признак?
Выберите правильный ответ. Задача регрессии - это:
Вероятность ошибочной классификации имеет вид:
Выберите правильный ответ. По обучающей выборке настраивается:
С помощью чего, из ниже перечисленного, можно определить сходство неизвестной и известной выборки?
Плотность распределения на имеет вид смеси распределений , где 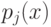 - это:
- это:
Выберите верные утверждения:
С чем, из ниже перечисленного сравнивают линейный классификатор?
Пусть есть задача с 2-мя классами . К какому классу будет относится алгоритм, если ?
Какая, из перечисленных ниже функций, соответствует линейному дискриминанту Фишера?
В формуле , что будет выступать в роли гиперпараметра?
Как называется величина объекта относительно алгоритма классификации ?
Если объекты классифицируется правильно и лежат в точности на границе разделяющей полосы, то их нахывают:
Какая формула, из ниже перечисленных, позволяет организовать итерационный процесс?
Что представляет собой матрица 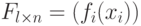 ?
?
Как называется метод, который удаляет те связи, к изменению которых функционал Q наименее чувствителен?
При каком условии в субквадратичном алгоритме многомерного шкалирования все точки будут "скелетными"?
Если есть два существенно различных метода обучения использующих разные наборы признаков, то это алгоритм:
Как определяется следующий функционал 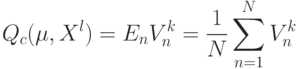 ?
?
Какие входные данные являются лишние в алгоритме жадного слияния зон?
По какой из формул параметрическое семейство Ф можно отнести к параметрическому семейству полуплоскостей?
Верно ли, что если правило , то объект будет определен в другом классе?
Выберите правило, которое подсчитывает долю голосов, относящих объект к каждому из классов:
Что из ниже перечисленного является моделью усреднения по блокам?
Какое условие, из ниже перечисленных, должно выполнятся, чтобы обеспечить достаточную величину шага, позволяющую справится с начальными условиями?
Что называют индикатором ошибки?
Что, из ниже перечисленного является достоинством алгоритма бустинга?
Укажите, что входит в преимущества байесовского подхода.
Какая функция, из перечисленных ниже, является кусочно-постоянной?
Какая величина называется гиперпараметром?
Что, из ниже перечисленного, является функцией активации?
Если строится вариационный ряд ошибок 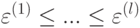 и отбрасывается некоторое количество t объектов с наибольшей ошибкой, тогда это называют:
и отбрасывается некоторое количество t объектов с наибольшей ошибкой, тогда это называют:
Что называют функцией роста множества алгоритмов А?
Функция роста множества всех конъюнкций ранга не выше K будет выглядеть как:
Как называется критерий, для которого выборка случайным образом разбивается на q непересекающихся блоков одинаковой длины 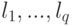 ?
?
Что, из ниже перечисленного принято решать достоинством решающего списка?
Что такое решающее дерево?
При каком n в карте сходства отображается результат многомерного шкалирования в виде плоского точечного графика?
Оценкой близости объекта к классу называется функция:
Что, из ниже перечисленного, является выходными данными в последовательном методе активных ограничений?
К какому методу обучения относится метод главных компонент?
Как будет выглядеть индикатор ошибки в случае классификации при конечном Y?
Что называют размерностью Вапника-Червоненкиса?
Если в семействе А выделена последовательность подсемейств возрастающей ёмкости 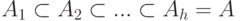 и в ней можно выбрать оптимальное подсемейство, для которого достигается минимальное значение правой части из формулы
и в ней можно выбрать оптимальное подсемейство, для которого достигается минимальное значение правой части из формулы 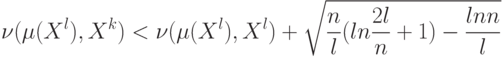 , то этот метод называют:
, то этот метод называют:
Что, из ниже перечисленного характеризует статический критерий?
Выберите верное определение коллаборативной фильтрации.
Какое правило означает следующая формула  ?
?
Небольшое число объектов с большими отрицательными отступами называют:
Что , из ниже перечисленного, служит целями кластеризации?
Как называется процедура создающая 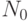 индивидов в алгоритме CCEL?
индивидов в алгоритме CCEL?
Что должно поступать на вход в алгоритме жадного добавления?
Что, из ниже перечисленного является определением критерия замены?
Как называется технология основанная на правилах морфологии языка?
В чём заключается задача кластеризации?
В какой функции множества нулей и единиц линейно неразделимы?
Какой метод представляет собой итерационный процесс смены поколений?
Что является недостатком тривиальной рекомендующей системой?
Что характеризует гипотеза условной независимости вида: 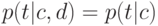 ?
?
Как называется критерий 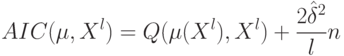 ?
?
Если известны и , то минимум среднего риска не будет достигнут при:
Какие, ниже перечисленные, недостатки можно отнести к методу потенциальных функций?
Что представляют векторы 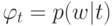 в пространстве терминов
в пространстве терминов  ?
?
Что представляет собой матрица 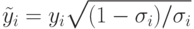 ?
?