При больших наборах данных MAP, какой из алгоритмов (мaximum likelihood, maximum a posteriori) будет эффективнее при условии нахождении глобальных максимумов?
При больших наборах данных MAP, какой из алгоритмов (мaximum likelihood, maximum a posteriori) будет эффективнее при условии нахождении глобальных максимумов?
Выберите оптимальный параметр для следующей модели согласно принципу ML (Maximum Likelihood / Максимальное правдоподобие): "Вероятность того что идет дождь если есть тучи сильнее, чем вероятность того что идет дождь, если туч нет":
Принцип Maximum Likelihood
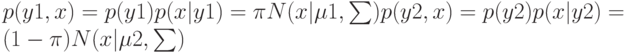
. Функция правдоподобия
![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png)
. Максимизируя

, в результате имеем одну из составляющих ?
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8), при этом известно, что первый и третий примеры относятся к классу "1", а второй и четвертый – к классу "0". Проведите процедуру отбора признаков (feature selection) методом minimum redundancy maximum relevance (mRMR), используя логарифм по основанию 2. Укажите, какие признаки нужно оставить:
Напишите название подхода иерархической кластеризации, при использовании которого перед началом кластеризации все объекты считаются отдельными кластерами, а затем, в ходе алгоритма, объединяются.
Дан единичный квадрат с координатами вершин (0;0), (0;1), (1;1), (1;0). При этом первая и третья вершины относятся к классу "-1", а вторая и четвертая – "1". Требуется построить классификатор, получающий на входе координату вершины, а на выходе дающий метку класса (задача XOR). Применим алгоритм градиентного бустинга (gradient boosting) с функцией потерь L(y,h)=ln(1+exp(-2*y*h)). Очевидно, h0(x)=const=0. Далее, выбираем в качестве a1 функцию, равную -1 левее разделяющей границы, проходящей через точки (1/2;0) и (0;1/2), и 1 в противном случае. Найдите итоговый коэффициент перед функцией a1 с учетом коэффициента регуляризации (shrinkage) 0,55.
Рассмотрим многослойный персептрон, состоящий из вытянутых в линейную цепочку 10 нейронов (один из них входной, один выходной, а 8 образуют 8 скрытых слоев). Для коррекции весов используется алгоритм обратного распространения ошибки (back propagation). Функция ошибки среднеквадратическая. Значения весов и ошибка на выходе не превышают по модулю единицы. Выберите, при каких значениях сигнала на входе градиент на входе может превысить 0,0001.

