В формуле линейной модели "W" означает следующее
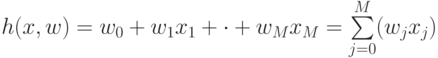
При каких условиях подход Maximum a posteriori (MAP) выигрывает перед Maximum Likelihood (ML)
При больших наборах данных MAP, какой из алгоритмов (мaximum likelihood, maximum a posteriori) будет эффективнее при условии нахождении глобальных максимумов?
При больших наборах данных MAP, какой из алгоритмов (мaximum likelihood, maximum a posteriori) будет эффективнее при условии нахождении глобальных максимумов?
Выберите оптимальный параметр для следующей модели согласно принципу ML (Maximum Likelihood / Максимальное правдоподобие): "Вероятность того что идет дождь если есть тучи сильнее, чем вероятность того что идет дождь, если туч нет":
Основный принцип, который используется в машинном обучении – это принцип:
Для чего используется логарифм правдоподобия Бернулли?
Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8), при этом известно, что первый и третий примеры относятся к классу "1", а второй и четвертый – к классу "0". Проведите процедуру отбора признаков (feature selection) методом minimum redundancy maximum relevance (mRMR), используя логарифм по основанию 2. Укажите, какие признаки нужно оставить:
В документе d слово "кластер" встречается с частотой TF("кластер",d)=0,0125. Мы имеем возможность программным образом изучить миллион документов, и выяснить, что указанное слово встречается только в 100 из них. Вычислите TF-IDF слова "кластер" в документе d с точностью до двух знаков после запятой:
На электронную почту пришло письмо. Пусть X – бинарный признак, указывающий, содержит входящее письмо сочетание слов "вам оставили наследство" (=1), или нет(=0), а Y – класс письма, указывающий, спам это (=1), или нет (=0). Известно, что P(Y=1)=0,05, P(X=1|Y=1)=0,0001, P(X=1|Y=0)=0,00001, и в письме присутствует указанное словосочетание. Каким решающим правилом нужно воспользоваться – максимального правдоподобия (ML) или апостериорного максимума (MAP), чтобы определить, пришедшее письмо – спам или нет:

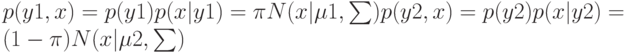 . Функция правдоподобия
. Функция правдоподобия ![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png) . Максимизируя
. Максимизируя  , в результате имеем одну из составляющих ?
, в результате имеем одну из составляющих ?
 (Верный ответ)
(Верный ответ)
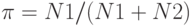 ,(Верный ответ)
,(Верный ответ)
