
Операцию редукции данных MPI_Reduce можно описать:
(Отметьте один правильный вариант ответа.)
Варианты ответа
как операцию передачи данных, при которой над собираемыми значениями осуществляется обработка, при этом частичные значения результатов редуцирования получают все процессы параллельной программы
операцию передачи данных, при которой над собираемыми значениями осуществляется та или иная обработка, при этом результат обработки получают все процессы
как операцию передачи данных, при которой над собираемыми значениями осуществляется обработка в процессе передачи, при этом результат обработки получает только ведущий процесс(Верный ответ)

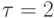 нсек. Латентности сети
нсек. Латентности сети 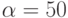 нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип
нсек. Пропускная способность сети 60 Мбайт/сек. Элементы матрицы имеют тип 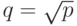 , где
, где