
Информация и данные - ответы
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 4?

Какие имена файлов соответствуют маске: "*.doc"?
У Вани 5 палочек, у Пети 6 палочек, у Игоря 20 палочек. Сколько палочек Ване и Пете нужно попросить у Игоря, чтобы записать в системе палочек произведение чисел 5 и 6?
Заработок наборщика текстов на компьютере зависит от количества знаков в тексте. Цена одного символа равна 10 копеек. Каков объём файла должен быть (в кодировке ASCII), чтобы наборщик текста получил за работу 1000 руб. Считаем, что 1 Кб=1000 байт.
Выпишите список последних 4-х слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие фразы соответствуют маске "?*и?*?"?
Какая цифра входит в запись числа в системе с основанием 7, если число в десятичной системе равно 74–1?
Толщина палочки 0,5 сантиметра. При записи числа в системе палочек расстояние между палочками 1 сантиметр. Какова длина записи числа 66?
Какие записи чисел некорректны в римской системе счисления?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 2?
Какие правила записи чисел справедливы для римской системы счисления?
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (4*4=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 2?
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (16*16=N), сделанной в системе счисления с основанием P = 2?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 4?
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 2?
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 2?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 4?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 4?
Сколько палочек понадобится для записи суммы двух чисел 5 и 7?
У Вани 5 палочек, у Пети 3 палочки, у Игоря 20 палочек. Сколько палочек Ване и Пете нужно попросить у Игоря, чтобы записать в системе палочек произведение чисел 5 и 3?
В системе палочек при записи числа палочки можно добавлять:
Укажите правильную запись числа 25 в римской системе счисления:
Какие правила записи чисел справедливы для римской системы счисления?
Какая цифра входит в запись числа в системе с основанием 8, если число в десятичной системе равно 86–1?
Число N равно 165 - 1. Какая цифра будет в его записи в системе с основанием 16?
Число N равно 55 + 1. Какие цифры будут в его записи в системе с основанием 5?
В каких системах счисления десятичное число 28 заканчивается цифрой 4?
В какой системе счисления десятичное число 55 заканчивается цифрой 2? Запишите это число в системе с минимально возможным основанием.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *?л??* .
Отметьте слово, которое будет идти последним в словаре:
Выпишите список всех слов длины 1 в алфавите {0, 1}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Выпишите список первых 3-х слов длины 4 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Выпишите список последних 5-и слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим два алфавита:  и
и 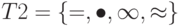 . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кто тот кот".
. Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кто тот кот".
Объём свободной памяти диска составляет 100 Мб. Считаем, что 1 Мб = 1000 Кб, 1 Кб=1000 байт. Один том частной библиотеки насчитывает в среднем 105 слов. Средняя длина слова 5 символов.Сколько томов поместится на диске (кодировка – Unicode)?
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 1 млн. слов каждый, можно хранить в памяти объёмом 10 Мб. Средняя длина слова в документах 5 символов.
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 4-х символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
В коде Морзе символы исходного текста кодируются словами, состоящими из двух символов – точка и тире. Если не считать разделители, то какова длина кодируемого слова?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "метро" без учета разделителей?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "весна" с учетом разделителей?
При записи кодом Брайля слова SOS длина переданного сообщения равна:
Рассмотрите код Брайля. Какова длина кода при кодировании слова "метроном" с учетом разделителей?
Для идентификации автомобилей использовались семизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, три последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения всех возможных номеров автомобилей в одном регионе?
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером. Имеется и компьютерный вариант хранения штрих-кодов.Каждая цифра кодируется минимально возможным набором битов. Штрих-код представляется целым числом байтов. Какова память достаточная для хранения информации о штрих-кодах всех возможных видов продукции 2-х предприятий-изготовителей?
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры номера паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры паспорта, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Какова память достаточная для хранения информации о всех паспортах, выданных в 60 регионах за один год?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какие слова соответствуют маске "?а?"?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие фразы соответствуют маске "Кто*Где*Когда*"?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие фразы соответствуют маске "?*?и*?"?
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается буквой "Д". Второй свидетель утверждал, что последней буквой в номере является буква "Я". На основании показаний была составлена маска "Д???Я". Какие номера соответствуют этой маске?
Какие имена файлов соответствуют маске: "*.docx"?
Какие имена файлов соответствуют маске: "*.*x"?
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "w=dd;"?
Какие наборы, составленные из множества двоичных слов длины 5 имеют расстояние большее или равное 3?
Какое слово нужно удалить из набора двоичных слов: s1=00011 s2=11011 s3=11000s4=00111
чтобы расстояние увеличилось на единицу.
Какие слова следует добавить в наборs1=00011 s2=11000s2=11011 s4=01010
чтобы расстояние набора не изменилось.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = л??о*.
Укажите правильную запись числа 250 в римской системе счисления:
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается буквой "А". Второй свидетель запомнил две цифры номера и марку машины. На основании показаний была составлена маска "А?37??". Какие номера соответствуют этой маске?
При передаче кодом Морзе двух текстов - "Кукушка" и "Тетерев" длины переданных сообщений будут:
Какое максимальное число можно записать в системе палочек, имея 3 палочки?
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 16?
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 10 с точностью до 5 знаков после запятой.
Сколько двоек в записи числа в системе с основанием 3, которое в десятичной системе равно 36-1?
Сколько слов длины 4 в алфавите, содержащем 1 символ?
Чему равно N в записи (4*4=N), сделанной в системе счисления с основанием P = 10?
Сколько слов длины 16 в алфавите, содержащем символы {+, 0, 1}?
Чему равно в десятичной системе число: 223, заданное в троичной системе?
Число N = 27 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Даны десятичные числа 202 и 300. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 4.
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Деакодируйте фразу: 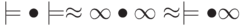 .
.
Число N = 10011101101записано в системе счисления с основанием 2. Запишите его в системе P = 5.
Вычислите значение выражения: 21108 - 101116. Запишите его в десятичной системе счисления.
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 10?
Перечислены цифры числа в системе счисления с основанием P = 4, начиная с младшей, - {3, 2, 3, 2}. Запишите число в десятичной системе.
Сколько слов длины меньше чем 2 в алфавите, содержащем 2 символа?
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:11110111100000111111100111
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 9. Декодируйте слово "qnuuxiex um".
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации о 100 городах?
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 20?
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 20?
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 16?
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 10?
Чему равна разность между числом СC в шестнадцатеричной системе счисления и числом СC в римской системе?
Чему равна разность между числом СC в шестнадцатеричной системе счисления и числом СC в римской системе?
Запишите число 2014 в римской системе счисления.
Чему равно число 10 в системе с основанием 2?
Чему равно число 1000 в системах с основанием 16?
Найти разность N – M, где N = 1001 в восьмеричной системе, M = 200 в шестнадцатеричной системе. Ответ дать в десятичной системе
Чему равно в десятичной системе число: 445, заданное в системе с основанием 5?
Сколько единиц в записи числа в системе с основанием 2, которое в десятичной системе равно 210-1?
Сколько нулей в записи числа в системе с основанием 2, которое в десятичной системе равно 210?
Сколько единиц в записи числа в системе с основанием 3, которое в десятичной системе равно 35+1?
Сколько семерок в записи числа в системе с основанием 8, которое в десятичной системе равно 88-1?
Число N равно 47. Сколько цифр будет в его записи в системе с основанием 4?
Число N равно 87. Сколько единиц будет в его записи в системе с основанием 8?
Число N равно 58. Сколько нулей будет в его записи в системе с основанием 5?
Число N равно 28 + 1. Сколько единиц будет в его записи в двоичной системе?
Число N равно pk + 1. Сколько единиц будет в его записи в системе с основанием p?
Число N равно pk - p. Сколько нулей будет в его записи в системе с основанием p и k > 2?
Число N = 1365. Запишите его в системе с основанием 8.
Число N = 2248. Запишите его в системе с основанием 4.
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 2.
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 8.
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 16.
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 8.
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 8.
Перечислены цифры числа в двоичной системе, начиная с младшей, - {1, 0, 1, 0, 1}. Запишите число в десятичной системе.
Перечислены цифры числа в системе счисления с основанием P = 8, начиная со старшей, - {1, 7, 5, 6}. Запишите число в десятичной системе.
Перечислены цифры числа в двоичной системе, начиная с младшей, - {1, 1, 1, 0, 1}. Запишите число в десятичной системе.
Перечислены цифры числа в системе счисления с основанием P = 20, начиная со старшей, - {A, 1, 0}. Запишите число в десятичной системе.
Вычислите значение выражения: 10113 + 21104. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 211020 - 101116. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 21103 - 10114. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 101116 - 10118 - 10116. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 1014 - 1013 - 1012. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 2268 < x < 100101012.
Определите число целочисленных решений неравенства: 122223 <= x <= 2428.
Сколько существует систем счисления, в которых десятичное число 225 заканчивается цифрой 4?
Число N = 10011101101 записано в системе счисления с основанием 2. Запишите его в системе P = 4.
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 4.
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 4.
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 20.
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 3.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 16.
Число N = 10011 записано в системе счисления с основанием 2. Запишите его в системе P = 4.
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 5.
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 20.
Число N = 10011101101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода группы цифр в цифру.
Число N = 3210 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1001101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода группы цифр в цифру.
Число N = 10002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 27, используя упрощенное правило перевода группы цифр в цифру.
Число N = 222222 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 27, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Число N = 123 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Число N = 717 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N = 77 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 20 с точностью до 2 знаков после запятой.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 2 с точностью до 5 знаков после запятой.
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 16 с точностью до 1 знака после запятой.
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 8 с точностью до 1 знака после запятой.
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,101 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 2. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Дробь N = 0,11 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 2. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Число N = 7,7 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Сколько различных слов длины 2 можно построить в алфавите мощности 6?
Вам необходимо декодировать некоторый текст S - упшлб. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10110 01001 10100 10000 00001 .
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«веист»=«ствие», K2=011100010001000
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; N = 128
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010001 1100100101001 010100100101 011100101001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 13, M = 8, P = 12, Q = 50000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100110, 001110, 101010, 010010)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций:
k = IndexOf(S, «:»);
S1 = Substring(S, k+2);
Сколько слов длины 2 в алфавите, содержащем 1 символ?
Сколько слов длины 8 в алфавите, содержащем 2 символа?
Сколько слов длины меньше чем 8 в алфавите, содержащем 2 символа?
Сколько слов длины 8 в алфавите, содержащем символы {+, 0, 1}?
Сколько слов длины меньше чем 2 в алфавите, содержащем символы {а, м, п}?
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «мама»?
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 3, закодируйте фразу "учите информатику".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 9, закодируйте фразу "learn computer science".
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 7. Декодируйте слово "еётдзтдёужщлужщпсъ".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 3. Декодируйте слово "frpsxwhucvflhqfh".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "информатика и математика".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "Vojjna i mir".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Day and Night".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Декодируйте фразу "Гоод луцк".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Декодируйте фразу: 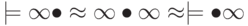 .
.
Даны два алфавита P = {а, б, р, к, ф } и Q{ 1, 2}. Создайте эффективную таблицу кодировки 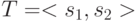 , где
, где 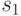 = "абркф", а
= "абркф", а 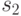 – это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q. Закодируйте текст "брак".
– это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q. Закодируйте текст "брак".
Даны два алфавита P = {а, б, р, к } и Q{ 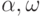 }. Таблица кодировки . Здесь = "абрк", а = "
}. Таблица кодировки . Здесь = "абрк", а = "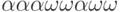 ". Декодируйте текст "\alpha\omega\omega\alpha\alpha\alpha\omega\omega".
". Декодируйте текст "\alpha\omega\omega\alpha\alpha\alpha\omega\omega".
Текст "сорока" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки 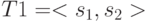 , где = "корса", – это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q{0,1}. Таблица кодировки
, где = "корса", – это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q{0,1}. Таблица кодировки 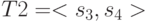 , где
, где  = "01",
= "01",  = "АВ"Какой текст придет к получателю сообщения?
= "АВ"Какой текст придет к получателю сообщения?
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2. В результате был получен текст "корос". Декодируйте его.Таблица кодировки , где = "корс", = "1234". Таблица кодировки , где = "1234", = "сорк".Какой текст получит получатель сообщения?
Сколько слов длины 5 в алфавите мощности 2?
Сколько слов длины меньше чем 5 в алфавите мощности 3?
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код буквы "и".
Для трехбуквенного алфавита {А, Н, Т} используется кодировка А – 01, Т – 10, Н – 001. Какой код минимальной длины следует задать для кодировки буквы Е, добавляемой в алфавит?
Для трехбуквенного алфавита используется кодировка: а – 0, м – 10, п – 100. Какой код минимальной длины следует выбрать для символа "п", обеспечив однозначное декодирование?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: дока и око. Запишите результат шестнадцатеричными цифрами
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: 6CC20CD Декодируйте текст.
Определите максимальный префикс слов: "кино", "кио", "киль"
Расположите в словарном порядке: "победа", "обеда", "беда", "еда", "да"
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 3?
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 50?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 60?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 140?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КММ?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова УМХ?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова ХУК?
6 предприятий, расположенные в различных странах, выпускают по 200 различных видов продукции. Код каждого вида продукции состоит из 7 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код продукции представляется целым числом байтов. Сколько байтов необходимо для хранения всех кодов?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов. Бланк в цифровом виде представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации об одном участнике?
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Какова память в байтах требуется для хранения цифровой информации об одном городе?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса – число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации одной строки каталога?
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 10.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации об одном городе?
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации 2-х бланков?
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Какая маска отвергнет все слова данного множества? В ответе укажите номер маски.
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docxРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска примет все имена файлов данного множества за одним исключением – "медведь.txt? В ответе укажите номер маски.
Число 123, запишите в двоичном виде, добавив в конец бит с контрольной суммой.
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:11110110100000101111001010001101
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Даны два двоичных числа одинаковой длины:s1=111001110;s2=111010110;
Вычислите расстояние по Хэммингу между ними.
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 20
Дан набор десятичных чисел: 120, 126, 204. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Дано множество двоичных слов длины 2:00 01 11 10
Сколько 2-элементных наборов с расстоянием 1 можно из них построить?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2 = S1 + " - красный нос!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = S1 + " - красный нос!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"мороз" в строку "мороз - морозко".Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 4, начиная с позиции 28, будет выделена из строки:морозные узоры – творенье мороза!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 7, начиная с позиции 9 из строки:Мороз – красный нос!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Peplace позволяет заменить все вхождения подстроки другой подстрокой Определите, какая строка будет получена при замене строки "роз" строкой "тор" в строке: "мороз - морозко!".
Сколько различных слов длины 2 можно построить в алфавите мощности 3?
Вам необходимо декодировать некоторый текст S - яспцр. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 01110 10010 00011 00110 10010.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«бклу»«кубл», K2=11001001
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; S = ссср
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010001 1100100101001 010100100101 011100101001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 53, M = 12, P = 20, Q = 2000000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100011, 101000, 010101, 010010)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение:
Мои любимые игры: «Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «:»);
S1 = Insert(S, k+2, «Баскетбол, » );
Текст "слово" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки , где = "влопс", = " " .Таблица кодировки , где = "
" .Таблица кодировки , где = " ", = "брник".Какой текст придет к получателю сообщения?
", = "брник".Какой текст придет к получателю сообщения?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 10?
Алфавит Т содержит следующие 5 символов: {пробел, и, к, о, т}. Для кодирования текстов в алфавите Т используется неравномерный код, удовлетворяющий условию Фано: {0, 10, 110, 1110, 1111}. Между символами алфавита Т и кодами установлено соответствие, учитывающее частоту вхождения символов в тексты: {пробел – 0.25, т – 0.22, и – 0.2, о - 0.18, к – 0.15}. Декодируйте текст: 111111010 11001111111010
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «амам»?
Какое слово нужно удалить из набора двоичных слов: s1=00011 s2=11000s3=11011s4=00101
чтобы расстояние увеличилось на единицу.
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 16?
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 3.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = S1 + "ные узоры – творение " + S1 + "а!"?
Сколько существует систем счисления, в которых десятичное число 55 заканчивается цифрой 2?
Число N = 1101101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода группы цифр в цифру.
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации 10-и бланков?
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 10 с точностью до 3 знаков после запятой.
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:110001110101010110110000111111000001
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Для пятибуквенного алфавита используется кодировка: а – 00, м – 10, п – 110, и – 111, пробел - 1101. Какой код минимальной длины следует выбрать для символа "пробел", обеспечив однозначное декодирование?
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 2 с точностью до 5 знаков после запятой.
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 20?
Вычислите значение выражения: 1015 - 1014 - 1013. Запишите его в десятичной системе счисления.
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 4?
Перечислены цифры числа в системе счисления с основанием P = 4, начиная с младшей, - {3, 2, 1, 0, 3}. Запишите число в десятичной системе
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2.В результате был получен текст "ВАААВВАВААААААВ". Декодируйте его.Таблица кодировки , где = "камус", – это слова, составленные из алфавита Q{1,0}, записанные в порядке возрастания их значений.Таблица кодировки , где = "01", = "АВ". Какой текст получит получатель сообщения?
Какое слово следует добавить в наборs1=000 s2=111s3=101
чтобы расстояние набора не изменилось.
Сколько слов длины 2 в алфавите, содержащем 2 символа?
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 20?
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 100000 слов каждый, можно хранить в памяти объёмом 20 Мб. Средняя длина слова в документах 5 символов.
Какой набор, составленный из множества двоичных слов длины 3 имеет расстояние большее или равное 2?
Чему равна разность между числом СCC в шестнадцатеричной системе счисления и числом СCC в римской системе?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова ККУ?
Перечислены цифры числа в системе счисления с основанием P = 16, начиная с младшей, - {2, 2, A}. Запишите число в десятичной системе.
Число N = 7,7 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 20.
Отметьте слово, которое будет идти первым в словаре:
Сколько слов длины меньше чем 2 в алфавите мощности 5?
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 8.
Число N = 77 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "ddd=dd+d;"?
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 15, закодируйте фразу "учите информатику".
Текст "сорок" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки , где = "корс", = "1234". Таблица кодировки , где = "1234", = "срок".Какой текст придет к получателю сообщения?
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 8 с точностью до 1 знака после запятой.
Число N = 123 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 20?
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 2?
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (16*16=N), сделанной в системе счисления с основанием P = 16?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 20?
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 4?
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 4?
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 16?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 20?
Толщина палочки 0,5 сантиметра. При записи числа в системе палочек расстояние между палочками 1 сантиметр. Какова длина записи числа 76?
В системе палочек при записи числа палочки можно добавлять:
Чему равна разность между числом С в римской системе и числом С в шестнадцатеричной системе счисления?
Запишите число 1812 в римской системе счисления.
Укажите правильную запись числа 150 в римской системе счисления:
Чему равно число 10 в системах с основанием 20?
Чему равно число 1000 в системах с основанием 8?
Найти разность N – M, где N = 400 в восьмеричной системе, M = 100 в шестнадцатеричной системе. Ответ дать в десятичной системе
Чему равно в десятичной системе число:FF16, заданное в системе с основанием 16?
Сколько единиц в записи числа в системе с основанием 3, которое в десятичной системе равно 35?
Сколько двоек в записи числа в системе с основанием 3, которое в десятичной системе равно 37-1?
Сколько единиц в записи числа в системе с основанием 3, которое в десятичной системе равно 310-1?
Сколько нулей в записи числа в системе с основанием 2, которое в десятичной системе равно 27-1?
Сколько единиц в записи числа в системе с основанием 8, которое в десятичной системе равно 85-1?
Число N равно 87. Сколько цифр будет в его записи в системе с основанием 8?
Число N равно 210. Сколько единиц будет в его записи в системе с основанием 2?
Число N равно pk – 1. Сколько единиц будет в его записи в системе с основанием p> 2?
Число N равно 87 - 1. Какая цифра будет в его записи в системе с основанием 8?
Число N равно 310 + 1. Какие цифры будут в его записи в системе с основанием 3?
Число N = 1365. Запишите его в системе с основанием 16.
Число N = 2248. Запишите его в системе с основанием 3.
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 16.
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 3.
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 4.
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 3.
Перечислены цифры числа в системе счисления с основанием P = 8, начиная с младшей, - {3, 4, 7, 4, 6}. Запишите число в десятичной системе
Перечислены цифры числа в троичной системе, начиная со старшей, - {1, 2, 2, 1, 1}. Запишите число в десятичной системе.
Перечислены цифры числа в двоичной системе, начиная со старшей, - {1, 0, 1, 1}. Запишите число в десятичной системе.
Вычислите значение выражения: 211016 - 101120. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 10118 - 10116 - 10115. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 10116 - 10110 - 1018. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 110100102 < x < D616.
Определите число целочисленных решений неравенства: 304 <= x <= 218.
Сколько существует систем счисления, в которых десятичное число 73 заканчивается цифрой 1?
В каких системах счисления десятичное число 73 заканчивается цифрой 1?
В какой системе счисления десятичное число 37 заканчивается цифрой 5? Запишите это число в системе с минимально возможным основанием.
Число N = 10011101101записано в системе счисления с основанием 2. Запишите его в системе P = 20.
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 16.
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 20.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 8.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 5.
Число N = 1101101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1122 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 27, используя упрощенное правило перевода группы цифр в цифру.
Число N = 10011101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 8, используя упрощенное правило перевода группы цифр в цифру.
Число N = 11111111 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода группы цифр в цифру.
Число N = 177 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Число N = 123 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N = A11 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N =717 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 4 с точностью до 1 знака после запятой.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 20 с точностью до 5 знаков после запятой.
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 20 с точностью до 2 знаков после запятой.
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,11 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 8. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Число N = A,A записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Сколько различных слов длины 4 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - бф ьл. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 00101 10000 01110 00010 11100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«азор»«зрао», K2=10001101
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 3; N = 101
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1111000 0110110 1111011 1111110 1000111 0110101 0100000
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 45, M = 10, P = 12, Q = 2500000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100011, 101000, 010101, 010010)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций:
k = IndexOf(S, «:»);
S1 = Substring(S, k+2);
Сколько слов длины 16 в алфавите, содержащем 1 символ?
Сколько слов длины меньше чем 4 в алфавите, содержащем 2 символа?
Сколько слов длины 1 в алфавите, содержащем символы {+, 0, 1}?
Отметьте слово, которое будет идти вторым в словаре:
Выпишите список первых 3-х слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 8, закодируйте фразу "учите информатику".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 8, закодируйте фразу "learn computer science".
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 5. Декодируйте слово "шьйт ъдчасе".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 7. Декодируйте слово "olhs oghukgclhs o".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "Война и мир".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "Moskva slezam ne verit".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Good luck".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Декодируйте фразу "Студентс".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кто кок то"
Даны два алфавита P = {а, б, р, к, ф } и Q{ 0, 1}. Создайте эффективную таблицу кодировки , где = "абркф", а – это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q. Закодируйте текст "брак".
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2. В результате был получен текст "АВВААВАВАААBAAAВАА". Декодируйте его.Таблица кодировки , где = "корса", – это слова, составленные из алфавита Q{1,0}, записанные в порядке возрастания их значений.Таблица кодировки , где = "01", = "АВ".Какой текст получит получатель сообщения?
Сколько слов длины 3 в алфавите мощности 5?
Сколько слов длины меньше чем 4 в алфавите мощности 5?
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код слова "ма".
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 1 млн. слов каждый, можно хранить в памяти объёмом 40 Мб. Средняя длина слова в документах 5 символов.
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 7-и символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
Выберите правильные варианты ответа:
Рассмотрите код Морзе. Какова длина кода при кодировании слова "зима" с учетом разделителей?
При передаче кодом Брайля двух текстов - "Кукушка" и "Тетерев" длины переданных сообщений будут:
Рассмотрите код Брайля. Какова длина кода при кодировании слова "лето"?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Декодируйте текст: 11001011101001111011110101
Для семибуквенного алфавита используется кодировка: а – 01, о – 101, к – 1100, и – 1111, д – 1101, н – 1110, пробел - 00. Какой код минимальной длины следует выбрать для символа "и", обеспечив однозначное декодирование?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: фонд и ад. Запишите результат шестнадцатеричными цифрами.
Определите максимальный префикс слов: "проспект", "просто", "прогноз"
Расположите в словарном порядке: "мариновать", "марка", "маразм", "марать"
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 8?
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 40?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 20?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КУК?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова ХКМ?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КУМ?
В городе N имеется 10 округов, в состав которых входит 125 муниципальных образований. Код каждого муниципального образования состоит из 11 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код муниципального образования представляется целым числом байтов. Сколько байтов необходимо для хранения всех кодов?
Для идентификации автомобилей использовались восьмизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, четыре последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения всех возможных номеров автомобилей в одном регионе?
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером. Имеется и компьютерный вариант хранения штрих-кодов.Каждая цифра кодируется минимально возможным набором битов. Штрих-код представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 300 штрих-кодов?
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры номера паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры паспорта, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Какова память достаточная для хранения информации о всех паспортах, выданных в 60 регионах за три года?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов.. Бланк в цифровом виде представляется целым числом байтов. Какова память в килобайтах достаточна для хранения цифровой информации об участниках 20 школ региона, если от каждой школы представлены по 100 участников?
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации о 1000 городов?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса –число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации одной строки каталога?
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 20.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о двух городах?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие фразы соответствуют маске "*компьютер*безопасность*"?
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается с "Б5". Второй свидетель утверждал, что кроме цифры 5 в номере есть цифра 7, но не запомнил ее местоположение. На основании показаний были составлены две маски: "Б5?7??" и "Б57???". Какие номера соответствуют одной из этих масок?
Какие имена файлов соответствуют маске: "*.xls*"?
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Какая маска примет все слова, кроме слова "порт"? В ответе укажите номер маски.
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска примет имя файла – "победа.doc", отвергнув остальные имена данного множества? В ответе укажите номер маски.
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "Аdddww"?
Число 116, запишите в двоичном виде, добавив в конец бит с контрольной суммой
Даны два двоичных числа одинаковой длины:s1=110001110;s2=101010110;
Вычислите расстояние по Хэммингу между ними.
Даны десятичные числа 200 и 300. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Даны двоичные числа: s1=01011s2=11111s3=01110s4=10101
Вычислите расстояние для этого набора.
Дан набор десятичных чисел: 120, 126, 200. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Какие наборы, составленные из множества двоичных слов длины 4 имеет расстояние большее или равное 3?
Дано множество двоичных слов длины 5:00011 11011 11001 00111
Сколько 2-элементных наборов с расстоянием 3 можно из них построить?
Какое слово нужно удалить из набора двоичных слов:s1=01111s2=11100s3=01100s4=10111
чтобы расстояние увеличилось на единицу.
Какие слова следует добавить в наборs1=00011 s2=11000s3=11011s4=00101
чтобы расстояние набора не изменилось.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2 = S1 + " - " + S1 + "ко" + "!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = S1 + " - " + S1 + "ко" + "!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 7, начиная с позиции 8, будет выделена из строки:мороз – красный нос .Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 2, начиная с позиции 9 из строки:Морозы - морозы!.Нумерация символов в строке начинается с нуля.
Сколько различных слов длины 4 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S = 01111 10000 01001 01100 00110 10000.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S =?а?а*.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«азор»«зрао», K2=10001101
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 3; S = ром
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1101000 0110110 1111011 0111100 1000111 0110101 1110001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 37, M = 5, P = 14, Q = 850000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100011, 101000, 010101, 111111)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S1 имеет значение: «Мои любимые предметы:»
Строка S2 имеет значение: «Математика»
Строка S3 имеет значение: «Литература»
Определите значение строки S в результате выполнения следующих операций над строками:
S = S1 + « » + S2 + «, » + S3 + «!»
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 2, начиная с позиции 0, будет выделена из строки:Ой, морозы, морозы!.Нумерация символов в строке начинается с нуля.
Объём свободной памяти диска составляет 100 Мб. После проведения процедуры очистки диска свободная память увеличилась на 20%. Сколько 20-ти символьных слов поместится в этой памяти (в кодировке Unicode), считая, что 1 Кб=1000 байт, 1 Мб = 1000 Кб?
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Letter and Digit".
Выпишите список последних 5-и слов длины 4 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Число N = 123 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 20.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о семи городах?
Чему равно N в записи (4*4=N), сделанной в системе счисления с основанием P = 16?
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 2?
Чему равно N=16*16 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 16?
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 16?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 2?
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 16?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 2?
Чему равна разность между числом СCC в шестнадцатеричной системе счисления и числом СCC в римской системе?
Чему равно число 10 в системе с основанием 8?
Чему равно число 1000 в системах с основанием 20?
Найти разность N – M, где M = 200 в восьмеричной системе, N = 100 в шестнадцатеричной системе. Ответ дать в десятичной системе
Сколько единиц в записи числа в системе с основанием 2, которое в десятичной системе равно 210?
Сколько единиц в записи числа в системе с основанием 2, которое в десятичной системе равно 210+1?
Сколько нулей в записи числа в системе с основанием 2, которое в десятичной системе равно 210+1?
Сколько единиц в записи числа в системе с основанием 8, которое в десятичной системе равно 88-1?
Число N равно 35. Сколько цифр будет в его записи в системе с основанием 3?
Число N равно 77. Сколько нулей будет в его записи в системе с основанием 7?
Число N равно pk. Сколько единиц будет в его записи в системе с основанием p?
Число N равно 2k + 2. Сколько единиц будет в его записи в системе с основанием 2 и k> 2?
Число N равно 47 - 1. Какие цифры будут в его записи в системе с основанием 4?
Число N = 2248. Запишите его в системе с основанием 8.
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 2.
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 4.
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 3.
Перечислены цифры числа в системе счисления с основанием P = 16, начиная с младшей, - {4, 4, A}. Запишите число в десятичной системе
Перечислены цифры числа в системе счисления с основанием P = 8, начиная со старшей, - {5, 7, 5}. Запишите число в десятичной системе.
Вычислите значение выражения: 101116 + 211020. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 21108 - 10115. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 10114 - 10113 - 10112. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 1008 < x < 4016.
Сколько существует систем счисления, в которых десятичное число 37 заканчивается цифрой 5?
В какой системе счисления десятичное число 28 заканчивается цифрой 4? Запишите это число в системе с минимально возможным основанием.
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 20.
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 3.
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 2.
Число N = 10011 записано в системе счисления с основанием 2. Запишите его в системе P = 3.
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16.
Число N = 122102 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 9, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1101101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 8, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1001101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 300210 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 77 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 16 с точностью до 1 знака после запятой.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 10 с точностью до 1 знака после запятой.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 8 с точностью до 5 знаков после запятой.
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 4 с точностью до 2 знаков после запятой.
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 10 с точностью до 1 знака после запятой.
Дробь N = 0,101 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 16. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Дробь N = 0,11 записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 4. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Сколько различных слов длины 2 можно построить в алфавите мощности 3?
Вам необходимо декодировать некоторый текст S - эпнфо.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 01110 01111 10000 01110 10001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *?а?а*.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«веист»=«итсев», K2=001010100000
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 3; N = 62
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
01010 10100 11011 10111 11110 11011 11100
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 17, M = 5, P = 12, Q = 1850000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(011100, 010111, 101010, 000000)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение:
Мои любимые игры: «Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «:»);
S1 = Insert(S, k+2, «Баскетбол, » );
Сколько слов длины 8 в алфавите, содержащем 1 символ?
Сколько слов длины 4 в алфавите, содержащем 2 символа?
Сколько слов длины меньше чем 16 в алфавите, содержащем 2 символа?
Сколько слов длины меньше чем 8 в алфавите, содержащем символы {а, м, п}?
Отметьте слово, которое будет идти первым в словаре:
Выпишите список всех слов длины 3 в алфавите {0, 1}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «мапа»?
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 5, закодируйте фразу "learn computer science".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я.
Декодируйте фразу "Дая анд Нигчт".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "око ток кок"
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Декодируйте фразу: 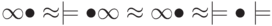 .
.
Даны два алфавита P = {о, г } и Q{0,1}. Создайте эффективную таблицу кодировки , где = "ог", а – это слова, составленные из алфавита Q, записанные в порядке возрастания их значений.Закодируйте текст "огого".
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2. В результате был получен текст "дурак". Декодируйте его.Таблица кодировки , где = "кумин", = "знаток". Таблица кодировки , где = "затон", = "куард".Какой текст получит получатель сообщения?
Сколько слов длины 5 в алфавите мощности 1?
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код слова "ми".
Заработок наборщика текстов на компьютере зависит от количества знаков в тексте. Цена одного символа равна 10 копеек. Каков объём файла должен быть (в кодировке Unicode), чтобы наборщик текста получил за работу 1000 руб. Считаем, что 1 Кб=1000 байт.
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 100000 слов каждый можно хранить в памяти объёмом 20 Мб. Средняя длина слова в документах 5 символов.
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 6-и символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "лето" без учета разделителей?
В коде Брайля символы исходного текста кодируются словами, состоящими из выпуклых и невыпуклых точек. Длина кодового слова равна:
Алфавит Т содержит следующие 5 символов: {пробел, а, и, м, п}. Для кодирования текстов в алфавите Т используется неравномерный код, удовлетворяющий условию Фано: {0, 10, 110, 1110, 1111}. Между символами алфавита Т и кодами установлено соответствие, учитывающее частоту вхождения символов в тексты: {пробел – 0.3, и – 0.27, а – 0.23, м - 0.11, п – 0.09}. Декодируйте текст: 11101101110110010011111101111110
Определите максимальный префикс слов: "проспект", "просто", "просо"
Расположите в словарном порядке: "мир", "абрикос", "море", "абориген", "абордаж", "монстр"
Алфавит состоит из 3-х букв {М, У, К }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 30?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 40?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 252?
В каждой из 5-ти библиотек города находится по 100000 книг. Код каждой книги состоит из 5 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код книги представляется целым числом байтов. Какую память достаточно иметь требуется иметь для хранения всех кодов?
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером. Имеется и компьютерный вариант хранения штрих-кодов.Каждая цифра кодируется минимально возможным набором битов. Штрих-код представляется целым числом байтов. Какова память достаточная для хранения информации о штрих-кодах всех возможных видов продукции 50-ти предприятий-изготовителей?
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации о 10 городах?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какие слова соответствуют маске "а?т"?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие слова соответствуют маске "*"??
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие записи соответствуют маске "?2*?1=??1"?
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается буквой "Л". Второй свидетель запомнил первую цифру номера. На основании показаний была составлена маска "Л2????". Сколько номеров в базе данных соответствует маске?
Какие имена файлов соответствуют маске: "*.???"?
Какие имена файлов соответствуют маске: "*.xlsx"?
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docxРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска примет имена файлов - "бедлам.docx", и "бред.docx", отвергнув остальные имена данного множества? В ответе укажите номер маски.
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "www"?
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:111001111110100111101110
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Даны два двоичных числа одинаковой длины:s1=110001110;s2=110001111;
Вычислите расстояние по Хэммингу между ними.
Даны двоичные числа: s1=011s2=111s3=001s4=100
Вычислите расстояние для этого набора.
Дан набор десятичных чисел: 120, 124, 200. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Какое слово нужно удалить из набора двоичных слов: s1=000111 s2=110001s3=110111
чтобы расстояние увеличилось.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2 = "Ой, " + S1 + "ы, " + S1 + "ы!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"мороз" в строку "Ой, мороз, мороз, не морозь меня!".Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 4, начиная с позиции 11, будет выделена из строки:Мороз - воевода!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Peplace позволяет заменить все вхождения подстроки другой подстрокой. Определите, какая строка будет получена при замене строки "красный" строкой "синий" в строке: "мороз – красный нос!"
Сколько различных слов длины 3 можно построить в алфавите мощности 6?
Вам необходимо декодировать некоторый текст S - ъыьъэ.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10001 01001 10001 10010 00110 01100 00001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = L?*D*?.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 3; N = 101
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010111 1100100101100 010100110001 011100101001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 17, M = 7, P = 20, Q = 50000
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «:»);
S1 = Insert(S, k+2, «Баскетбол, » );
Число N = 1A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером.Каждая цифра кодируется независимо минимально возможным набором битов. Штрих-код представляется целым числом байтов. Сколько байтов необходимо для хранения одного штрих-кода?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса –число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 10-ти классах одной школы в данном городе?
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 2?
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе P = 2.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 20.
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 3?
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 2.
Сколько существует систем счисления, в которых десятичное число 28 заканчивается цифрой 4?
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Sun and Moon".
Какие имена файлов соответствуют маске: "*.doc?"?
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 16?
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 4?
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 4?
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 16
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (16*16=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 2?
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 16?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 3?
Сколько нулей в записи числа в системе с основанием 3, которое в десятичной системе равно 310-1?
Какая цифра входит в запись числа в системе с основанием 4, если число в десятичной системе равно p10–1?
Число N равно 53. Сколько единиц будет в его записи в системе с основанием 5?
Число N равно pk. Сколько нулей будет в его записи в системе с основанием p?
Число N равно 37 – 1. Сколько единиц будет в его записи в троичной системе?
Число N равно pk + p. Сколько единиц будет в его записи в системе с основанием p и k > 2?
Число N = 2248. Запишите его в системе с основанием 2.
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 2.
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 16.
Вычислите значение выражения: 10112 + 21103. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 21103 - 10112. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 21105 - 10118. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 10116 - 10115 - 10114. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 122223 < x < 2428.
Определите число целочисленных решений неравенства: 1008 <= x <= 4016.
В какой системе счисления десятичное число 55 заканчивается цифрой 2?
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 4.
Число N = 10011записано в системе счисления с основанием 2. Запишите его в системе P = 5.
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 8.
Число N = 10011101101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 8, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1001101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 8, используя упрощенное правило перевода группы цифр в цифру.
Число N = 177 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N = 27 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 10 с точностью до 3 знаков после запятой.
Дробь N = 0,101 записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 2. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Сколько различных слов длины 3 можно построить в алфавите мощности 6?
Вам необходимо декодировать некоторый текст S - прспт. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10001 01001 10001 10010 00110 01100 00001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = D + D = DD.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«кноры»«нркыо», K2=100010011000001
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; S = ссср
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1101100 0110110 1110011 0111100 1000111 0110101 1110001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 21, M = 7, P = 7, Q = 1850000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111000, 110011, 011110, 010011)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Баскетбол, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Баскетбол»);
S1 = Replace(S, k, 9, «Компьютерные игры» );
Сколько слов длины 0 в алфавите, содержащем 2 символа?
Сколько слов длины меньше чем 4 в алфавите, содержащем символы {а, м, п}?
Отметьте слово, которое будет идти вторым в словаре:
Выпишите список всех слов длины 2 в упорядоченном алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «пама»?
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 15. Декодируйте слово "аоъоьанчнаябт".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающим с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "тёмная ночь".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "informatika i matematika",
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Декодируйте фразу "Яоур цчоице".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кок око кот"
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Декодируйте фразу:  ;
;
Даны два алфавита P = {а, б, р, с } и Q{0,1}. Создайте эффективную таблицу кодировки , где = "абрс", а – это слова, составленные из алфавита Q, записанные в порядке возрастания их значений.Закодируйте текст "барбара".
> Даны два алфавита P = {а, б, р, к, ф } и Q{ 0, 1}. Таблица кодировки . Здесь ="абркф", а = "000001010011100". Декодируйте текст "011010000001".
Сколько слов длины 4 в алфавите мощности 5?
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код слова "ам".
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 100000 слов каждый можно хранить в памяти объёмом 30 Мб. Средняя длина слова в документах 5 символов.
Определите максимальный префикс слов: "бам", "бампер"
Расположите в словарном порядке: "лучик", "лучеиспускание", "лук", "лучок", "лучистый"
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 242?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КУМ?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова МУК?
В каждой из 10-ти библиотек города находится по 100000 книг. Код каждой книги состоит из 5 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код книги представляется целым числом байтов. Какую память достаточно иметь для хранения всех кодов?
Для идентификации автомобилей использовались восьмизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, четыре последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения одного номера автомобиля?
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры номера паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры паспорта, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Сколько байтов необходимо для хранения информации о паспорте?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов. Бланк в цифровом виде представляется целым числом байтов. Какова память в килобайтах достаточна для хранения цифровой информации об участниках 2-х регионов, если в каждом из этих регионов 20 школ, и от каждой школы представлены по 100 участников?
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 20.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о двух городах?
Число 119, запишите в двоичном виде, добавив в конец бит с контрольной суммой.
Дан набор десятичных чисел: 122, 128, 200. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Какие наборы, составленный из множества двоичных слов длины 4 имеют расстояние большее или равное 2?
Какие слова следует добавить в наборs1=000111 s2=110001s3=110111
чтобы расстояние набора не изменилось.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = S1 + " - " + "воевода " + "дозором обходит владенья свои!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"розы" в строку "морозные узоры – творенье мороза!".Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 2, начиная с позиции 1, будет выделена из строки:Мороз – морозко!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Peplace позволяет заменить все вхождения подстроки другой подстрокой. Определите, какая строка будет получена при замене строки "роз" строкой "тор" в строке: "морозные узоры – творенье мороза!"
Сколько различных слов длины 2 можно построить в алфавите мощности 5?
Вам необходимо декодировать некоторый текст S - эпнфо.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10110 00110 01011 11100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«екст»«ксте», K2=0001101100
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1101100 0110110 1110011 0111100 1000111 0110101 1110001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 23, M = 9, P = 20, Q = 850000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(001100, 010101, 100001, 101000)
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 2?
Число N = EEE записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 5-и символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
Вычислите значение выражения: 10118 + 211016. Запишите его в десятичной системе счисления.
Число N = 27 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Сколько слов длины 16 в алфавите, содержащем 2 символа?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 16?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "терем" с учетом разделителей:
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 16?
Даны двоичные числа: s1=010s2=111s3=001s4=100
Вычислите расстояние для этого набора
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код слова "им".
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 16?
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно число 1000 в системах с основанием 2?
Чему равно в десятичной системе число: 556, заданное в системе с основанием 6?
Число N равно 27 – 1. Сколько единиц будет в его записи в двоичной системе?
Число N равно 83 + 1. Какие цифры будут в его записи в системе с основанием 8?
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 8.
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 20.
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 2.
Перечислены цифры числа в системе счисления с основанием P = 4, начиная со старшей, - {3, 2, 2, 1, 3}. Запишите число в десятичной системе.
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе P = 2.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 2.
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 3.
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 20.
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 16.
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 8.
Число N = 122102 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 27, используя упрощенное правило перевода группы цифр в цифру.
Число N = 10011101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 123 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N = ABC записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 2 с точностью до 3 знаков после запятой.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 16 с точностью до 1 знака после запятой.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 16 с точностью до 5 знаков после запятой.
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 2 с точностью до 3 знаков после запятой.
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 16 с точностью до 5 знаков после запятой.
Вам необходимо декодировать некоторый текст S - тмпгп. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«опрст»=«тсрпо», K2=100011101010001101011
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111010, 101100, 011111, 010001)
Сколько слов длины меньше чем 1 в алфавите, содержащем символы {+, 0, 1}?
Выпишите список первых 4-х слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «папа»?
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 9, закодируйте фразу "учите информатику".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 15. Декодируйте слово "wt cotjtfmqcsm".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Декодируйте фразу "Леттер анд Дигит".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Декодируйте фразу: 
Текст "сумка" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки , где = "камус", – это слова, стоящие в вершине упорядоченного по возрастанию списка, составленного из алфавита Q{0,1}. Таблица кодировки , где = "01", = "АВ".Какой текст придет к получателю сообщения?
При передаче текста из 10 символов в коде Морзе потребуется передать сообщение, содержащее знаков:
Рассмотрите код Морзе. Какова длина кода при кодировании слова "осень" без учета разделителей?
Алфавит включает 7 символов, кодируемые следующими двоичными словами :{00, 01, 100, 1100, 1101, 1110, 1111}. В алфавит добавляется еще один символ. Какой код минимальной длины можно выбрать для этого символа, не нарушая условия Фано?
Для семибуквенного алфавита используется кодировка: а – 01, о – 101, к –100, и – 1111, д – 1101, н – 1110, пробел - 1100. Какой код минимальной длины следует выбрать для символа "пробел", обеспечив однозначное декодирование?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: дафна и инаф. Запишите результат шестнадцатеричными цифрами.
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: D7F92139FДекодируйте текст.
Расположите в словарном порядке: "километр", "килограмм", "киль", "килька"
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова ХУХ?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова МММ?
В городе N имеется 5 округов, в состав которых входит 50 муниципальных образований. Код каждого муниципального образования состоит из 6 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код муниципального образования представляется целым числом байтов. Сколько байтов необходимо для хранения всех кодов?
Для идентификации автомобилей использовались семизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, три последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения одного номера автомобиля?
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером. Имеется и компьютерный вариант хранения штрих-кодов.Каждая цифра кодируется минимально возможным набором битов. Штрих-код представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 500 штрих-кодах?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса –число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации 5-и строк каталога?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие записи соответствуют маске "5*5=?"?
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Задайте свою маску, которая будет принимать слова "портфель" и "ортогональ", отвергая другие слова данного множества.
Число 243, запишите в двоичном виде, добавив в конец бит с контрольной суммой.
Даны два двоичных числа одинаковой длины:s1=110001111;s2=101010100;
Вычислите расстояние по Хэммингу между ними.
Даны десятичные числа 116 и 200. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Какие наборы, составленные из множества двоичных слов длины 4 имеют расстояние большее или равное 3?
Дано множество двоичных слов длины 4:0001 1101 1100 0011 Сколько 2-элементных наборов с расстоянием 4 можно из них построить?
Какое слово нужно удалить из набора двоичных слов: s1=000111 s2=001111s3=110001s4=110111
чтобы расстояние увеличилось на единицу.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = "Ой, " + S1 + "ы, " + S1 + "ы!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"вода" в строку "мороз - воевода!".Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 2, начиная с позиции 8 из строки:морозы, морозы!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Replace позволяет заменить все вхождения подстроки другой подстрокой. Определите, какая строка будет получена при замене строки "роз" строкой "тор" в строке: "мороз - воевода!"
Вам необходимо декодировать некоторый текст S = 10010 01110 10111 01010 00001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = LDD?LL.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«трио»«орти», K2=00110110
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 3; N = 62
Какое слово в этом порядке имеет номер N?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(011100, 010111, 101010, 101101)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Определите значение строки S в результате выполнения следующих операций над строками:
S = «Миша» + « + » + «Маша» + « = » + «любовь» + «!»
Сколько различных слов длины 5 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - гшбю. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *а??*а.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«декор»«екорд», K2=011000010001100
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = { м, о, р, с }; m = 3; N = 53
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
010110100 100111011 010101110 111010110 010110111 111111000
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 21, M = 7, P = 7, Q = 1850000
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Insert(S, 7, «Андрей + » );
Сколько различных слов длины 3 можно построить в алфавите мощности 5?
Вам необходимо декодировать некоторый текст S - тмпгп. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10000 00110 11000 00110 01101 01001 00110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S =*LLDDD*.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«агилнс»«иагнсл», K2=011001000101010100
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = папа
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1100000000000 1101000001000 0010101000100 0101100101101
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 3, M = 7, P = 10, Q = 500000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(110011,101010,011110, 010111)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций:
k = IndexOf(S, «:»);
S1 = Substring(S, k+2);
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Какая маска примет все слова данного множества? В ответе укажите номер маски.
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 5.
6 предприятий, расположенные в различных странах, выпускают по 300 различных видов продукции. Код каждого вида продукции состоит из 7 символов. Каждый символ – это десятичная цифра от 0 до 9 либо одна из трех букв – А, О, И. Символ кодируется минимально возможным набором битов. Код продукции представляется целым числом байтов. Сколько байтов необходимо для хранения всех кодов?
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 16?
Сколько различных слов длины 6 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - тегйд. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 01111 10000 01001 01100 00110 10000.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«екст»«ксте», K2=0001101100
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = { м, о, р, с }; m = 3; N = 53
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110110001 1101100101100 0101101011110
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 53, M = 12, P = 20, Q = 2000000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(011100, 010111, 101010, 101101)
Сколько слов длины 2 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - щцыцл.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; N = 128
Какое слово в этом порядке имеет номер N?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(011100, 010111, 101010, 000000)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Баскетбол, Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Шахматы»);
S1 = Remove(S, k, 8 );
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 2.
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docxРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска отвергнет все имена файлов данного множества? В ответе укажите номер маски.
Даны два алфавита P = {о, г } и Q{0,1}. Таблица кодировки . Здесь ="ог", а s_2=="01". Декодируйте текст "01010".
Дробь N = 0,11 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 16. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 7?
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 5.
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 5. Декодируйте слово "sj jwexfcesj jw"
Документ содержит 100000 слов, средняя длина которых составляет 5 символов. Считая, что 1 Кб=1000 байт, 1 Мб=1000 Кб, оцените объём памяти в кодировке Unicode, достаточный для хранения документа.
В коде Брайля символы исходного текста кодируются словами, состоящими из двух символов – точка выпуклая, точка невыпуклая. Если не считать разделителя, то какова длина слова?
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Какова память в байтах требуется для хранения цифровой информации о 20 – ти городах?
Определите число целочисленных решений неравенства: 2528 < x <201113.
Вычислите значение выражения: 10120 - 10116 - 1018. Запишите его в десятичной системе счисления.
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "[fgh](w,w)"
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: FBDA41DДекодируйте текст.
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docxРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска примет первые 4 имени файла, отвергнув три последних имени данного множества? В ответе укажите номер маски.
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 16?
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 4?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса – число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 2-х классах одной школы в данном городе?
Число N = 10011101101записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 1A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 3?
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 20?
Чему равно N в записи (16*16=N), сделанной в системе счисления с основанием P = 4?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 10?
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 3?
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 20?
Чему равна разность между числом С в римской системе и числом С в шестнадцатеричной системе счисления?
Запишите число 2999 в римской системе счисления.
Какие записи чисел некорректны в римской системе счисления?
Какие правила записи чисел справедливы для римской системы счисления?
Чему равно число 1000 в системах с основанием 3?
Число N = 1365. Запишите его в системе с основанием 4.
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 2.
Перечислены цифры числа в системе счисления с основанием P = 16, начиная со старшей, - {2, 3, 7}. Запишите число в десятичной системе.
Вычислите значение выражения: 10115 + 21108. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 1016 - 1015 - 1014. Запишите его в десятичной системе счисления.
В каких системах счисления десятичное число 225 заканчивается цифрой 4?
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 5.
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8.
Число N = 10011записано в системе счисления с основанием 2. Запишите его в системе P = 8.
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 20.
Число N = 122102 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 27, используя упрощенное правило перевода группы цифр в цифру.
Число N = 2210 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = 10011101 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода группы цифр в цифру.
Число N = 11111111 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 8, используя упрощенное правило перевода группы цифр в цифру.
Число N = 123 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Число N = A11 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Число N = EEE записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 2 с точностью до 3 знаков после запятой.
Дробь N = 0,A записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 20 с точностью до 2 знаков после запятой.
Дробь N = 0,101 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 8. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Дробь N = 0,11 записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 2. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Вам необходимо декодировать некоторый текст S = 10111 01001 10001 01011 01110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = л??о*?.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«блотуф»«уфблот», K2=011010001100000101
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 237
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010111 1100100101100 010100110001 011100101001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 33, M = 5, P = 15, Q = 1800000
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Replace(S, 7, 4, «Наташа» );
Сколько слов длины 0 в алфавите, содержащем 1 символ?
Сколько слов длины 1 в алфавите, содержащем 2 символа?
Сколько слов длины 2 в алфавите, содержащем символы {+, 0, 1}?
Отметьте слово, которое будет идти последним в словаре:
Выпишите список последних 3-х слов длины 4 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
В списке слов длины 4 в упорядоченном алфавите {а, м, п} какой номер слова «апап»?
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 15, закодируйте фразу "learn computer science".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "chto poseesh’ to pozhnyosh’".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Your choice".
Даны два алфавита P = {а, б, р, к } и Q{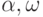 }. Создайте эффективную таблицу кодировки , где = "абрк", а – это слова, составленные из алфавита Q, записанные в порядке возрастания их значений.Закодируйте текст "брак".
}. Создайте эффективную таблицу кодировки , где = "абрк", а – это слова, составленные из алфавита Q, записанные в порядке возрастания их значений.Закодируйте текст "брак".
Сколько слов длины меньше чем 3 в алфавите мощности 5?
Считая, что 1 Кб = 1000 байт, 1 Мб = 1000 Кб и кодировка текстов произведена в Unicode, оцените,сколько документов, состоящих из 100000 слов каждый, можно хранить в памяти объёмом 10 Мб. Средняя длина слова в документах 5 символов.
При записи текста из 10 символов в коде Брайля потребуется сообщение, содержащее знаков:
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: данон и канон. Запишите результат шестнадцатеричными цифрами
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: 36E242E5Декодируйте текст.
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 10?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КМУ?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КХЭ?
Для идентификации автомобилей использовались семизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, три последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения всех возможных номеров автомобилей в одном регионе?
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры серии паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры серии, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Какова память достаточная для хранения информации о всех паспортах одной серии?
В некотором каталоге содержится список «малых» городов с населением от 20 000 до 80 000 жителей включительно. Названия городов даются как в кириллице (33 прописные буквы), так и в латинице (26 букв). Каталог имеет поля: имя города (в кириллице) - 15 символов, имя города (в латинице) - 15 символов, число жителей в городе. Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации о 10 городах?
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 20.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 10-и городах?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какие слова соответствуют маске "????"?
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается с "Б5". Второй свидетель утверждал, что кроме цифры 5 в номере есть цифра 7, но не запомнил ее местоположение. На основании показаний были составлены две маски: "Б5?7??" и "Б57???". Сколько номеров в базе данных соответствует этим маскам?
Какие имена файлов соответствуют маске: "*.???"?
Даны десятичные числа 202 и 304. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Дано множество двоичных слов длины 3:000 011 111 110 101
Сколько 2-элементных наборов с расстоянием 2 можно из них построить?
Какие слова можно добавить в наборs1=01111s2=11100s3=01100s4=10111
чтобы расстояние набора не изменилось.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2 = "Ой, " + S1 + ", " + S1 + ", " + "не " + S1 + "ь " + "меня!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Какова длина переменной S2, где S2 = "Ой, " + S1 + ", " + S1 + ", " + "не " + S1 + "ь " + "меня!"?
Сколько различных слов длины 3 можно построить в алфавите мощности 3?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *?а?а*.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«блотуф»«уфблот», K2=011010001100000101
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 10
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
0001100 1100110 1111110 0110001 1100011 0110110 1110001
При передаче какого пакета возникла ошибка?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(011001, 110001, 010101,101101)
Рассмотрите код Морзе. Какова длина кода при кодировании слова "осень" с учетом разделителей?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 4?
Дан набор десятичных чисел: 124, 130, 208. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Число N = 4A0 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4.
Дробь N = 0,101 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 4. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Число N = 7,7 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Какая маска примет все слова, кроме слов "порт" и "ортогональ"? В ответе укажите номер маски.
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 16?
Чему равно N в записи (9*9=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 4?
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 2?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 2?
Толщина палочки 0,5 сантиметра. При записи числа в системе палочек расстояние между палочками 1 сантиметр. Какова длина записи числа 250?
В системе палочек при записи числа палочки можно добавлять:
Чему равно в десятичной системе число: 667, заданное в системе с основанием 7?
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 3.
Перечислены цифры числа в системе счисления с основанием P = 20, начиная со старшей, - {A, 0, H}. Запишите число в десятичной системе.
Перечислены цифры числа в системе счисления с основанием P = 8, начиная с младшей, - {1, 3, 5}. Запишите число в десятичной системе.
Вычислите значение выражения: 21105 - 10114. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 1018 - 1017 - 1016. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 2528 <= x <= 201113.
В какой системе счисления десятичное число 73 заканчивается цифрой 1? Запишите это число в системе с минимально возможным основанием.
Число N = 10011101101записано в системе счисления с основанием 2. Запишите его в системе P = 16.
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 2.
Число N = 470 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4.
Число N = 10011записано в системе счисления с основанием 2. Запишите его в системе P = 20.
Число N = 177 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 4, используя двоичную систему в качестве промежуточной.
Число N = 717 записано в системе счисления с основанием 8. Запишите его в системе счисления с основанием P = 16, используя двоичную систему в качестве промежуточной.
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 3 с точностью до 5 знаков после запятой.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 20 с точностью до 1 знака после запятой.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 4 с точностью до 5 знаков после запятой.
Дробь N = 0,101 записана в системе счисления с основанием 16. Запишите ее в системе счисления с основанием P = 4. Используйте упрощенный способ перевода, заменяя цифру группой цифр системы P.
Дробь N = 0,11 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 4. Используйте упрощенный способ перевода, заменяя группу цифр цифрой системы P.
Сколько различных слов длины 3 можно построить в алфавите мощности 3?
Вам необходимо декодировать некоторый текст S - ъыьъэ.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 01110 10010 00011 00110 10010.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = ?*а??*а*?.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«вести»«итсев», K2=001010100000
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010001 1100100101000 010100100001 011100101001
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 37, M = 5, P = 14, Q = 850000
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Баскетбол, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Баскетбол»);
S1 = Replace(S, k, 11, «Биология» );
Примечание: Функция Replace(S, k, m, R) в строке S заменяет подстроку длины m, начинающуюся с k-го символа, подстрокой R. Нумерация символов строки начинается с нуля.
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 8. Декодируйте слово "ёжуеиуежрхьцшфзърты".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 8. Декодируйте слово "owwlhtbks".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Запишите кириллицей фразу "Students".
Рассмотрим задачу транслитерации – записи текста в латинице символами кириллицы. В отличие от обратной задачи – записи кириллицы латиницей, - где существует несколько различных стандартов, при записи текстов латиницы кириллицей стандартов не существует. Будем пользоваться следующей таблицей перевода, позволяющей однозначно кодировать и декодировать тексты латиницы:Вначале символы, допускающие близкое звучание:A - А , B - Б, C - Ц, D - Д, E - Е, F - Ф, G - Г, I - И, J - Й, K - К, L - Л, M - М, N - Н, O - О, P - П, R - Р, S - С, T - Т, U - У, Z – З
.Для оставшихся 5 символов выберем следующее соответствие:H - Ч, Q - Ю, W - Ш, X - Х, Y - Я
.Декодируйте фразу "Сун анд Моон".
Даны два алфавита P = {а, б, р } и Q{0,1}. Создайте эффективную таблицу кодировки , где = "абр", а – это слова, составленные из алфавита Q, записанные в порядке возрастания их значений.Закодируйте текст "бра".
Текст "умник" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки , где = "кумин", = "злато". Таблица кодировки , где = "затол", = "куард".Какой текст придет к получателю сообщения?
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2. В результате был получен текст "ВВАВВААВАА". Декодируйте его.Таблица кодировки , где = "корс", – это слова, составленные из алфавита Q{1,0}, записанные в порядке возрастания их значений. Таблица кодировки , где = "01", = "АВ".Какой текст получит получатель сообщения?
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 3-х символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "зима" без учета разделителей?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "лето" с учетом разделителей?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: дик и аид. Запишите результат шестнадцатеричными цифрами.
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры номера паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры паспорта, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра или число кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Какова память достаточная для хранения информации о всех паспортах, выданных в 60 регионах за 10 лет?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов. Бланк в цифровом виде представляется целым числом байтов. Какова память в килобайтах достаточна для хранения цифровой информации об участниках 2-х регионов, если в каждом из этих регионов 20 школ, и от каждой школы представлены по 50 участников?
Число 115, запишите в двоичном виде, добавив в конец бит с контрольной суммой.
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:1111011110100000111111110011101011110010
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Даны десятичные числа 200 и 302. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Даны двоичные числа: s1=0110s2=1110s3=0011s4=1001
Вычислите расстояние для этого набора.
Дано множество двоичных слов длины 3:000 011 111 110 101
Сколько 2-элементных наборов с расстоянием 1 можно из них построить?
Какие слова нужно удалить из набора двоичных слов: s1=000111 s2=001111s3=110001s4=110111
чтобы расстояние увеличилось на единицу.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2= S1 + " - " + "воевода " + "дозором обходит владенья свои!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"нос" в строку "мороз – красный нос!".Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Peplace позволяет заменить все вхождения подстроки другой подстрокой. Определите, какая строка будет получена при замене строки "роз" строкой "тор" в строке: "морозы - морозы!"
Вам необходимо декодировать некоторый текст S = 10110 01001 10100 10000 00001 .
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«опрст»=«тсрпо», K2=100011101010001101011
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 13, M = 8, P = 12, Q = 50000
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Баскетбол, Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Математика»);
S1 = Remove(S, k, 11 );
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 3. Декодируйте слово "цъзрязвфезх".
Число N = 10011записано в системе счисления с основанием 2. Запишите его в системе P = 16.
Даны два алфавита P = {а, б, р, с } и Q{ 0, 1}. Таблица кодировки . Здесь ="абрс", а ="00011011". Декодируйте текст "011000".
Каталог городов, основанных в 20 - ом столетии имеет поля:название города – 15 буквенных символов, год основания – число от 0 до 99,количество театров – число от 0 до 20.Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о пяти городах?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 120?
Перечислены цифры числа в троичной системе, начиная со старшей, - {2, 0, 2, 1}. Запишите число в десятичной системе.
Чему равно 404 в записи, сделанной в системе счисления с основанием P = 4?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 30?
Выпишите список всех слов длины 2 в алфавите {0, 1}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 20?
Чему равно N в записи (4*4=N), сделанной в системе счисления с основанием P = 4?
Чему равно N в записи (5*5=N), сделанной в системе счисления с основанием P = 10?
Чему равно 505 в записи, сделанной в системе счисления с основанием P = 4?
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 10?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 10?
Запишите максимально допустимое число в римской системе счисления.
Чему равно число 10 в системе с основанием 4?
Число N = 1365. Запишите его в системе с основанием 2.
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 20.
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 20.
Вычислите значение выражения: 10114 + 21105. Запишите его в десятичной системе счисления.
Определите число целочисленных решений неравенства: 304 < x < 218.
Определите число целочисленных решений неравенства: 110100102 <=x <= D616.
Число N = 33020 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 8.
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 2.
Число N = 10002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 9, используя упрощенное правило перевода группы цифр в цифру.
Число N = 333333 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 20 с точностью до 2 знаков после запятой.
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 4 с точностью до 2 знаков после запятой.
Число N = A,A записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Сколько различных слов длины 8 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S = 10001 01011 01110 00011 01110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«векорт»«кврето», K2=010000011000101001100
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = рота
Какой номер в этом порядке у слова S?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 001100, 100001, 101100)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S1 имеет значение: «Мои любимые предметы:»
Строка S2 имеет значение: «Математика»
Строка S3 имеет значение: «Литература»
Определите значение строки S в результате выполнения следующих операций над строками:
S = S1 + « » + S2 + «, » + S3 + «!»
Сколько слов длины меньше чем 0 в алфавите, содержащем символы {а, м, п}?
Выпишите список первых 5-и слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "что посеешь то пожнёшь".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кок ток кот"
Сколько слов длины 5 в алфавите мощности 3?
Рассмотрите код Морзе. Какова длина кода при кодировании слова "метро" с учетом разделителей?
Рассмотрите код Брайля. Какова длина кода при кодировании слова "зима" с учетом разделителей?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 130?
Алфавит состоит из 5-ти букв { К, М, У, Х, Э }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова МЭМ?
Для идентификации автомобилей использовались восьмизначные номера. Два последних символа были цифрами и задавали номер региона, два первых символа были буквенными в алфавите из 30 символов, четыре последующих символа были цифровыми. Номер автомобиля кодируется минимально возможным числом битов, будучи затем представленным целым числом байтов. Сколько байтов необходимо для хранения всех возможных номеров автомобилей в одном регионе?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов.Бланк в цифровом виде представляется целым числом байтов. Какова память в килобайтах достаточна для хранения цифровой информации об участниках 10-ти школ региона, если от каждой школы представлены по 100 участников?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какие слова соответствуют маске "?ис?"?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие фразы соответствуют маске "*Любовь*ненависть*"?
Автомобильный номер состоит из 8 символов. Последние два символа задают номер региона. Второй, третий и четвертый символы – цифровые. Остальные три символа это буквы кириллицы (в номере используются 30 букв алфавита). Два свидетеля транспортного происшествия показали, что виновником аварии была машина данного региона. Первый свидетель утверждал, что номер машины начинается буквой "А". Второй свидетель запомнил две цифры номера и марку машины. На основании показаний была составлена маска "А?37??". Сколько номеров в базе данных соответствует маске?
Рассмотрим набор из 5-и масок:1. *орт*2. ?орт?3. ?*орт*4. *орт*?5. ?*орт*?Рассмотрим множество слов:{портфель, порт, ортогональ, кортик, сортировка, мортира}Какая маска примет все слова, кроме слова "ортогональ"? В ответе укажите номер маски.
Рассмотрим набор масок:1. *ед*.*2. *ед*.doc*3. ?*ед*.doc?4. ?ед?.doc*5. *ед*?.doc*6. ?*ед*?.docxРассмотрим множество имен файлов:{едоки.doc, единорог.docx, победа.doc, бедлам.docx, дед.doc, медведь.txt, бред.docx}Какая маска примет все имена файлов данного множества? В ответе укажите номер маски.
Даны десятичные числа 120 и 200. Постройте их двоичные образы s1 и s2 одинаковой длины. Вычислите расстояние между ними.
Какой набор, составленный из множества двоичных слов длины 2 имеет расстояние большее или равное 2?
Дано множество двоичных слов длины 4:0001 1101 1100 0011
Сколько 2-элементных наборов с расстоянием 2 можно из них построить?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Пусть переменная S1 = "мороз". Чему равно значение переменной S2, где S2 = S1 + "ные узоры – творение " + S1 + "а!"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 9, начиная с позиции 0 из строки:Морозные узоры – творенье мороза!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины.Функция Peplace позволяет заменить все вхождения подстроки другой подстрокой. Определите, какая строка будет получена при замене строки "роз" строкой "тор" в строке: "Ой, мороз, мороз, не морозь меня !"
Сколько различных слов длины 2 можно построить в алфавите мощности 4?
Вам необходимо декодировать некоторый текст S - чфщфй. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10111 01001 10001 01011 01110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *л??о*.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 16.
Рассмотрите код Морзе. Какова длина кода при кодировании слова "терем" без учета разделителей?
Чему равно 909 в записи, сделанной в системе счисления с основанием P = 20?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Зачастую необходимо определить, является ли одна строка частью другой строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Если вхождения нет, то результатом является значение -1. Определите индекс вхождения строки"розы" в строку "Ой, морозы, морозы!".Нумерация символов в строке начинается с нуля.
Вычислите значение выражения: 211016 - 10118. Запишите его в десятичной системе счисления.
Чему равно N в записи (16*16=N), сделанной в системе счисления с основанием P = 3?
Чему равно число 1000 в системах с основанием 4?
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 8.
Вычислите значение выражения: 10115 - 10114 - 10113. Запишите его в десятичной системе счисления.
Сколько существует систем счисления, в которых десятичное число 50 заканчивается цифрой 1?
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 8.
Число N = 3440 записано в системе счисления с основанием 5. Запишите его в системе счисления с основанием P = 3.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 8.
Дробь N = 0,125 записана в системе счисления с основанием 10. Запишите ее в системе счисления с основанием P = 4 с точностью до 2 знаков после запятой.
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 2 с точностью до 4 знаков после запятой.
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 4 с точностью до 5 знаков после запятой.
Сколько различных слов длины 2 можно построить в алфавите мощности 4?
Вам необходимо декодировать некоторый текст S - чкхсб.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 01111 00110 10000 00110 00011 01110 00101.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *л??о*.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«аезкр»«креза», K2=000100001011010
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с}; m = 4; N = 10
Какое слово в этом порядке имеет номер N?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 42, M = 9, P = 13, Q = 1500000
Сколько слов длины меньше чем 16 в алфавите, содержащем 2 символа?
Выпишите список первых 4-х слов длины 4 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 5, закодируйте фразу "учите информатику".
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 3, закодируйте фразу "learn computer science".
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "Москва слезам не верит".
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Закодируйте фразу: "кок тот кот"
Сколько слов длины меньше чем 5 в алфавите мощности 2?
Код кириллической строчной буквы "а" равен 1072 (в десятичной системе). Кодировка символов алфавита плотная. Это означает, что код символа алфавита на единицу больше кода предыдущего символа (алфавит упорядочен). В кириллице единственным исключением является буква "ё", у которой особый код. Зная код буквы "а", запишите в двоичной системе код буквы "м".
Рассмотрите код Морзе. Какова длина кода при кодировании слова "весна" без учета разделителей?
Алфавит состоит из 3-х букв { К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КМК?
Алфавит состоит из 4-х букв { К, М, У, Х } Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова КУМ?
Информация об учащихся школ города хранится в каталоге с полями: город – 15 буквенных символов,код школы – 3 буквенных символа, за которыми следует двузначное число, номер класса – число в интервале от 1 до 12, за которым следует одна буква,количество учащихся - число в интервале от 0 до 30. Буквенные символы – это символы алфавита из 33 букв.Каждое число кодируется минимально возможным набором битов. Строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 20-ти классах одной школы в данном городе?
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации о 10 пользователях за один год?
Какие имена файлов соответствуют маске: "*.doc*"?
Помимо специальных символов "?" и "*" в масках могут применяться и другие специальные символы. Символу "d" ставится в соответствие любая цифра. Символу "w" - цифра или буква латиницы или кириллицы. Совокупности символов, заключенных в квадратные скобки, [f, g, h] – соответствует любой из символов совокупности.Какие записи выделяет маска: "к[ои]т и л[еи]с"?
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины, начиная с заданной позиции. Определите, какая строка длины 6, начиная с позиции 21, будет выделена из строки:Ой, мороз, мороз, не морозь меня!.Нумерация символов в строке начинается с нуля.
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 14, начиная с позиции 4 из строки:Ой, мороз, мороз, не морозь меня!.Нумерация символов в строке начинается с нуля.
Сколько различных слов длины 2 можно построить в алфавите мощности 6?
Вам необходимо декодировать некоторый текст S = 10001 00101 00011 01001 00100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = D + D = DD.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; S = морс
Какой номер в этом порядке у слова S?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Баскетбол, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Баскетбол»);
S1 = Replace(S, k, 11, «Биология» );
Примечание: Функция Replace(S, k, m, R) в строке S заменяет подстроку длины m, начинающуюся с k-го символа, подстрокой R. Нумерация символов строки начинается с нуля.
Некоторый текст был дважды закодирован с использованием таблиц кодировки T1 и T2. В результате был получен текст "крнбн". Декодируйте его.Таблица кодировки , где = "влопс", = "".Таблица кодировки , где = " ", = "брник".
Сколько слов длины 2 в алфавите мощности 5?
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 4?
Число N в десятичной системе равно 1945. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 3.
Чему равно N в записи (7*7=N), сделанной в системе счисления с основанием P = 20?
Чему равно 606 в записи, сделанной в системе счисления с основанием P = 4?
Число N = 2248. Запишите его в системе с основанием 16.
Перечислены цифры числа в троичной системе, начиная с младшей, - {2, 2, 0, 1}. Запишите число в десятичной системе.
Перечислены цифры числа в системе счисления с основанием P = 4, начиная со старшей, - {1, 3, 1, 3}. Запишите число в десятичной системе.
В каких системах счисления десятичное число 37 заканчивается цифрой 5?
Число N = 10011101101 записано в системе счисления с основанием 2. Запишите его в системе P = 3.
Число N = 2212 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 9, используя упрощенное правило перевода группы цифр в цифру.
Число N = 222222 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 9, используя упрощенное правило перевода группы цифр в цифру.
Число N = ABC записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P
Число N = EEE записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 2, используя упрощенное правило перевода с заменой цифры группой цифр системы P.
Дробь N = 0,12 записана в системе счисления с основанием 3. Запишите ее в системе счисления с основанием P = 10 с точностью до 5 знаков после запятой с округлением.
Вам необходимо декодировать некоторый текст S - ьэюья. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
010110100 100111011 010101110 111010110 010110111 111111000
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 73, M = 6, P = 16, Q = 800000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 001110, 100001, 101101)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Баскетбол, Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Математика»);
S1 = Remove(S, k, 11 );
Сколько слов длины меньше чем 1 в алфавите, содержащем 2 символа?
Сколько слов длины 4 в алфавите, содержащем символы {+, 0, 1}?
Выпишите список последних 3-х слов длины 3 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим упорядоченный алфавит из 27 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 26 строчных букв латиницы. Используя код Цезаря со сдвигом k = 7, закодируйте фразу "learn computer science".
Даны два алфавита P = {а, б, р, к, ф } и Q{ 1, 2}. Таблица кодировки . Здесь ="абркф", а = "111112121122211". Декодируйте текст: "211121111122".
Сколько слов длины меньше чем 3 в алфавите мощности 4?
Рассмотрите код Брайля. Какова длина кода при кодировании слова "терем" с учетом разделителей?
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодируйте текст: ода и код. Запишите результат шестнадцатеричными цифрами.
Расположите в словарном порядке: "радуга", "бампер", "работа", "радость", "дуга", "бал"
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова МХМ?
Штрих-код, которым помечается продукция, состоит из 13 цифр. Первые две цифры штрих-кода означают страну изготовителя продукта;следующие пять - предприятие-изготовитель;еще пять - вид продукции;последняя цифра - контрольная, используемая для проверки правильности считывания штрих-кода сканером. Имеется и компьютерный вариант хранения штрих-кодов.Каждая цифра кодируется минимально возможным набором битов. Штрих-код представляется целым числом байтов. Какова память достаточная для хранения информации о штрих-кодах всех возможных видов продукции одного предприятия-изготовителя?
Даны два двоичных числа одинаковой длины:s1=110001111;s2=101010110;
Вычислите расстояние по Хэммингу между ними.
Вам необходимо декодировать некоторый текст S - тегйд. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«векорт»«кврето», K2=010000011000101001100
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Андрей + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Remove(S, 7, 9 );
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 16?
Число N = 1122 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 9, используя упрощенное правило перевода группы цифр в цифру.
Чему равно в десятичной системе число: 778, заданное в системе с основанием 8?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие слова соответствуют маске "*и*"?
Дробь N = 0,44 записана в системе счисления с основанием 8. Запишите ее в системе счисления с основанием P = 16 с точностью до 1 знака после запятой.
Выпишите список первых 5-и слов длины 4 в алфавите {а, м, п}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Используя код Цезаря со сдвигом k = 7, закодируйте фразу "учите информатику".
Чему равно N в записи (3*3=N), сделанной в системе счисления с основанием P = 2?
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 4?
Перечислены цифры числа в троичной системе, начиная с младшей, - {2, 2, 1, 0, 1}. Запишите число в десятичной системе
В какой системе счисления десятичное число 50 заканчивается цифрой 1? Запишите это число в системе с минимально возможным основанием.
Число N = 1002 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 4.
Число N = 332210 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = A,A записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = торт
Какой номер в этом порядке у слова S?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 17, M = 7, P = 20, Q = 50000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000101, 010011, 100000, 101110)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Insert(S, 7, «Андрей + » );
Текст "сорок" был закодирован с использованием таблицы кодировки T1. При передаче закодированного текста он был еще раз закодирован с использованием таблицы T2. Таблица кодировки , где = "корс", – это слова, составленные из алфавита Q{0,1}, записанные в порядке возрастания их значений. Таблица кодировки , где = "01", = "АВ".Какой текст придет к получателю сообщения?
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации 5-и бланков?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какое слово соответствует маске "и??с"?
Вам необходимо декодировать некоторый текст S = 00011 01110 01111 10000 01110 10001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = ?*о??*у*?.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«деикрт»«екртди», K2=101000011001100010
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
101 110 110 010 101
При передаче какого пакета возникла ошибка?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций:
k = IndexOf(S, «:»);
S1 = Substring(S, k+2);
Чему равно 707 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно A0A в записи, сделанной в системе счисления с основанием P = 2?
Чтобы заработать 1000 рублей в день, наборщик текстов знает, что объем файла должен быть 20Кб. Кодировка – Unicode. Сколько стоит набор одного символа текста? Считаем, что 1 Кб=1000 байт.
Чему равно N в записи (6*6=N), сделанной в системе счисления с основанием P = 10?
Чему равно N в записи (20*20=N), сделанной в системе счисления с основанием P = 3?
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 4.
Перечислены цифры числа в двоичной системе, начиная со старшей, - {1, 1, 0, 0, 1, 1}. Запишите число в десятичной системе.
Вычислите значение выражения: 21104 - 10113. Запишите его в десятичной системе счисления.
Вычислите значение выражения: 21104 - 10115. Запишите его в десятичной системе счисления.
В какой системе счисления десятичное число 225 заканчивается цифрой 4? Запишите это число в системе с минимально возможным основанием.
Число N = 10022012 записано в системе счисления с основанием 3. Запишите его в системе счисления с основанием P = 5.
Вам необходимо декодировать некоторый текст S - щцыцл.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1101000 0110110 1111011 0111100 1000111 0110101 1110001
При передаче какого пакета возникла ошибка?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100011, 101000, 010101, 111111)
В коде Морзе символы исходного текста кодируются словами, состоящими из точек и тире. Длина кодового слова, не учитывая разделителей, равна:
Выберите правильные варианты ответа:
Рассмотрите код Брайля. Какова длина кода при кодировании слова "мастер" с учетом разделителей?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 150
При работе со строковыми данными операция "+" означает конкатенацию (сцепление) строк. Функция Length позволяет определить длину строки. Функция IndexOf возвращает индекс первого вхождения строки S в строку Q. Функция Substring позволяет выделить строку заданной длины. Функция Remove позволяет удалить, начиная с заданной позиции строку заданной длины. Определите, какая строка будет получена после удаления строки длины 2, начиная с позиции 13 из строки:Мороз - морозко!.Нумерация символов в строке начинается с нуля.
Сколько различных слов длины 7 можно построить в алфавите мощности 2?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *2*0*1*4.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110110001 1101100101100 0101101011110
При передаче какого пакета возникла ошибка?
В каких системах счисления десятичное число 50 заканчивается цифрой 1?
Сколько слов длины 1 в алфавите, содержащем 1 символ?
Дробь N = 0,22 записана в системе счисления с основанием 4. Запишите ее в системе счисления с основанием P = 8 с точностью до 1 знака после запятой.
Число N = 1HG записано в системе счисления с основанием 20. Запишите его в системе счисления с основанием P = 3.
Чему равно 808 в записи, сделанной в системе счисления с основанием P = 2?
Толщина палочки 0,5 сантиметра. При записи числа в системе палочек расстояние между палочками 1 сантиметр. Какова длина записи числа 150?
У Вани 6 палочек, у Пети 3 палочки, у Игоря 20 палочек. Сколько палочек Ване и Пете нужно попросить у Игоря, чтобы записать в системе палочек произведение чисел 6 и 3?
Чему равно число 10 в системе с основанием 3?
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 3.
Перечислены цифры числа в системе счисления с основанием P = 16, начиная со старшей, - {A, B, C}. Запишите число в десятичной системе.
Вычислите значение выражения: 11102 - 10113. Запишите его в десятичной системе счисления.
Число N = 330 записано в системе счисления с основанием 4. Запишите его в системе счисления с основанием P = 5.
Число N = 11111111 записано в системе счисления с основанием 2. Запишите его в системе счисления с основанием P = 16, используя упрощенное правило перевода группы цифр в цифру.
Число N = ABC записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 8, используя двоичную систему в качестве промежуточной.
Сколько различных слов длины 7 можно построить в алфавите мощности 2?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S =?а?а*.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1100000000000 1101000001000 0010101000000 0101110101101
При передаче какого пакета возникла ошибка?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Баскетбол, Шахматы, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Шахматы»);
S1 = Remove(S, k, 8 );
При передаче кодом Морзе сигнала SOS с учетом разделителей длина переданного сообщения равна:
Алфавит Т содержит следующие 5 символов: {пробел, и, к, о, т}. Для кодирования текстов в алфавите Т используется неравномерный код, удовлетворяющий условию Фано: {0, 10, 110, 1110, 1111}. Между символами алфавита Т и кодами установлено соответствие, учитывающее частоту вхождения символов в тексты: {пробел – 0.25, т – 0.22, и – 0.2, о - 0.18, к – 0.15}. Декодируйте текст: 101110100111111010
Определите максимальный префикс слов: "радуга", "работа", "радость"
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 4?
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 4 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 60?
Нумерация паспортов состоит из трех групп цифр, первые две из которых (в сумме 4 цифры) обозначают серию паспорта, третья (из 6 цифр) — номер паспорта. Первые две цифры номера паспорта соответствуют коду региона, в котором выдан паспорт; третья и четвертая цифры паспорта, как правило, соответствуют последним двум цифрам года выдачи паспорта. Каждая цифра кодируется минимально возможным набором битов. Полный номер паспорта представляется целым числом байтов. Какова память достаточная для хранения информации о всех паспортах, выданных в 60 регионах за два года?
Вам необходимо декодировать некоторый текст S - ящьпь. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 620
Какое слово в этом порядке имеет номер N?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 43, M = 11, P = 10, Q = 750000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111010, 101100, 011111, 010001)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S1 имеет значение: «Мои любимые игры:»
Строка S2 имеет значение: «Шахматы»
Строка S3 имеет значение: «Волейбол»
Определите значение строки S в результате выполнения следующих операций над строками:
S = S1 + « » + S2 + «, » + S3 + «!»
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 16.
Чему равно число 10 в системе с основанием 16?
Перечислены цифры числа в системе счисления с основанием P = 20, начиная с младшей, - {G, 1, 1}. Запишите число в десятичной системе.
Число N = 10011101101записано в системе счисления с основанием 2. Запишите его в системе P = 8.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *да?* .
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 3; S = ром
Какой номер в этом порядке у слова S?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 11, M = 7, P = 17, Q = 1000000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(001100, 010101, 100001, 101000)
Для четырехбуквенного алфавита используется кодировка: а – 00, м – 10, п – 11, и - 101. Какой код минимальной длины следует выбрать для символа "и", обеспечив однозначное декодирование?
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 6?
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 50?
Перечислим основные поля бланка регистрации участника ЕГЭ: код региона (2 цифры), код образовательной организации (4 буквенных символа, за которыми следуют 2 цифры), номер класса (2 цифры)буква класса (1 буква), код предмета (2 буквенных символа), фамилия участника (12 буквенных символов).Буквенные символы это символы алфавита из 64 строчных и прописных букв кириллицы.Все символы, в том числе и цифры, кодируются независимо минимально возможным набором битов.. Бланк в цифровом виде представляется целым числом байтов. Сколько байтов необходимо для хранения цифровой информации о 100 участниках?
При построении маски используются как обычные, так и специальные символы. Специальному символу "?" соответствует любой символ алфавита – слово длины 1. Какие слова соответствуют маске "?а?"?
Сколько различных слов длины 8 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - чкхсб.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10001 00011 11111 01000 11100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 33, M = 5, P = 15, Q = 1800000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 001100, 100001, 101100)
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово. Какие фразы соответствуют маске "*да*нет*"?
Число N в десятичной системе равно 2014. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 20.
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: 1AF5E218F5EДекодируйте текст.
Число N в десятичной системе равно 1812. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 4.
Сколько различных слов длины 3 можно построить в алфавите мощности 5?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = L?*D*?.
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые предметы: Математика, Литература!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «:»);
S1 = Insert(S, k+2, «Баскетбол, » );
Рассмотрим два алфавита: и . Установим взаимно однозначное соответствие между алфавитами, когда i-му символу алфавита T1 соответствует i-й символ алфавита T2.Декодируйте фразу:
Рассмотрите код Брайля. Какова длина кода при кодировании слова "осень" с учетом разделителей?
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации об одном пользователе за один год?
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие фразы соответствуют маске "?и*?"?
Какие имена файлов соответствуют маске: "*.xls"?
Дан набор десятичных чисел: 122, 128, 204. Постройте их двоичные образы s1, s2 , s3 одинаковой длины. Вычислите расстояние для этого набора.
Какое слово нужно удалить из набора двоичных слов: s1=000 s2=111s3=101
чтобы расстояние увеличилось на единицу.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = л??о*?.
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 001110, 100001, 101101)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Substring(S, 7, 4)
Даны два алфавита P = {а, б, р, с } и Q{ 0, 1}. Таблица кодировки . Здесь ="абрс", а = "00011011". Декодируйте текст "01001001001000".
Число N = 1365. Запишите его в системе с основанием 3.
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 4.
Число N = A11 записано в системе счисления с основанием 16. Запишите его в системе счисления с основанием P = 4, используя упрощенное правило перевода с заменой цифры на группу цифр.
Вам необходимо декодировать некоторый текст S - яспцр. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«трио»«орти», K2=00110110
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 3; S = тор
Какой номер в этом порядке у слова S?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 011000, 100001, 111011)
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Substring(S, 7, 4)
При построении маски используются как обычные, так и специальные символы. Специальному символу "*" соответствует любое слово произвольной длины, в том числе и пустое слово, специальному символу "?" соответствует слово длины 1. Какие записи соответствуют маске "5+*=??"?
При передаче пакетов данных сопровождаемых контрольной суммой получены следующие результаты:1111111110100000001111110011111100110010
Бит с контрольной суммой добавлен в конец пакета. Сколько пакетов передано с ошибкой?
Число N в десятичной системе равно 1945. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 16.
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "Ljod i plamen’".
Дробь N = 0,6 записана в системе счисления с основанием 20. Запишите ее в системе счисления с основанием P = 8 с точностью до 5 знаков после запятой.
Какие имена файлов соответствуют маске: "*.*x"?
Сколько слов длины меньше чем 0 в алфавите, содержащем 2 символа?
Выпишите список всех слов длины 4 в алфавите {0, 1}, сохраняя упорядоченность слов. Слова в списке, разделяйте запятой и одним пробелом. Сам список заключите в фигурные скобки. Примером является запись самого алфавита.
Алфавит состоит из 3-х букв {К, М, У }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Какое слово в этом перечислении стоит под номером 5?
Сколько различных слов длины 3 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«кноры»«нркыо», K2=100010011000001
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1111000 0110110 1111011 1111110 1000111 0110101 0100000
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 17, M = 5, P = 12, Q = 1850000
Чему равно в десятичной системе число: 112, заданное в двоичной системе?
Чему равно N в записи (10*10=N), сделанной в системе счисления с основанием P = 3?
Для семибуквенного алфавита используется кодировка: а – 100, о – 101, к – 1100, и – 1111, д – 1101, н – 1110, пробел - 00. Какой код минимальной длины следует выбрать для символа "а", обеспечив однозначное декодирование?
Чему равно N в записи (8*8=N), сделанной в системе счисления с основанием P = 2?
Чему равно 202 в записи, сделанной в системе счисления с основанием P = 20?
Чему равно 303 в записи, сделанной в системе счисления с основанием P = 3?
Вычислите значение выражения: 101120 - 101116 - 10118. Запишите его в десятичной системе счисления.
Вам необходимо декодировать некоторый текст S = 10000 00110 11000 00110 01101 01001 00110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = ?*о??*у*?.
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 19, M = 9, P = 7, Q = 800000
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающий с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Запишите латиницей фразу "Лёд и пламень".
Вам необходимо декодировать некоторый текст S - прспт. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 00101 10000 01110 00010 11100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Код удовлетворяет условию Фано: {пробел – 00, а - 01, и – 100, о – 101, к – 1100, д – 1101, н – 1110, ф - 1111}. Закодированный текст записан шестнадцатеричными цифрами: 5D4865D Декодируйте текст.
Перечислены цифры числа в системе счисления с основанием P = 20, начиная с младшей, - {3, 4, H}. Запишите число в десятичной системе
Число N в десятичной системе равно 1812. Введите две старшие цифры этого числа при записи в системе счисления с основанием P = 16.
Дробь N = 0,1 записана в системе счисления с основанием 2. Запишите ее в системе счисления с основанием P = 8 с точностью до 1 знака после запятой.
Вам необходимо декодировать некоторый текст S - эчънъ.Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = LDD?LL.
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Андрей + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Remove(S, 7, 9 );
Алфавит состоит из 4-х букв { К, М, У, Х }. Слова длины 3 перечисляются в лексикографическом порядке. Нумерация слов начинается с единицы. Каков порядковый номер слова МКХ?
Вам необходимо декодировать некоторый текст S - упшлб. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *?л??* .
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«вести»«итсев», K2=001010100000
Цифровой бланк оплаты услуги за пользование электроэнергией имеет вид:лицевой счет – поле из 12 цифр,месяц – поле длины 8 в алфавите из 22 символов,год – поле из 2 цифр, показание счетчика – поле из 10 цифр,оплачено – число в интервале от 0 до 1000.Каждое поле кодируется минимально возможным набором битов. Одна строка каталога представляется целым числом байтов. Сколько байтов необходимо для хранения информации из одной строки бланка?
Чему равно N в записи (4*4=N), сделанной в системе счисления с основанием P = 2?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S =*LLDDD*.
Число 131, запишите в двоичном виде, добавив в конец бит с контрольной суммой.
Даны двоичные числа: s1=011s2=111s3=001s4=101
Вычислите расстояние для этого набора.
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с}; m = 4; N = 10
Какое слово в этом порядке имеет номер N?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1001110010001 1100100101000 010100100001 011100101001
При передаче какого пакета возникла ошибка?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Миша + Маша = любовь!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
S1 = Replace(S, 7, 4, «Наташа» );
Вам необходимо декодировать некоторый текст S - ящьпь. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10110 00110 01011 11100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«бклу»«кубл», K2=11001001
Сколько слов длины 0 в алфавите, содержащем символы {+, 0, 1}?
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 237
Какое слово в этом порядке имеет номер N?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111000, 110011, 011110, 010011)
Рассмотрим упорядоченный алфавит из 34 символов. Первым символом в этом алфавите идет символ "пробел" (пусто), а затем 33 строчные буквы кириллицы. Из агентурных источников стало известно, что при кодировании использовался код Цезаря со сдвигом k = 9. Декодируйте слово "ыщьмзсзыифицы".
Определите число целочисленных решений неравенства: 2268 <= x <= 100101012.
Сколько различных слов длины 2 можно построить в алфавите мощности 5?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 23, M = 9, P = 20, Q = 850000
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = рота
Какой номер в этом порядке у слова S?
Сколько различных слов длины 3 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«декор»«екорд», K2=011000010001100
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = папа
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
101 110 110 010 101
При передаче какого пакета возникла ошибка?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(110011,101010,011110, 010111)
Даны два двоичных числа одинаковой длины:s1=110001110;s2=111010110;
Вычислите расстояние по Хэммингу между ними.
Вам необходимо декодировать некоторый текст S = 01110 01111 10000 01110 10001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«веист»=«итсев», K2=001010100000
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; S = торт
Какой номер в этом порядке у слова S?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(100110, 001110, 101010, 010010)
Какие имена файлов соответствуют маске: "*.xls?"?
Чему равно в десятичной системе число: 334, заданное в четверичной системе?
Вам необходимо декодировать некоторый текст S = 10010 01110 10111 01010 00001.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
0001100 1100110 1111110 0110001 1100011 0110110 1110001
При передаче какого пакета возникла ошибка?
Рассмотрим задачу транслитерации – записи текста в кириллице символами латиницы. Единого стандарта не существует. Будем пользоваться следующим стандартом (Гост 16876-71, практически совпадающим с системой транслитерации Яндекса):А - A, Б – B, В – V, Г – G, Д – D, Е – E, Ё – JO, Ж – ZH, З – Z, И – I, Й – JJ, К – K, Л – L, М – M, Н – N, О – O, П – P, Р – R, С – S, Т – T, У – U, Ф – F, Х – KH, Ц – C, Ч – CH, Ш – SH, Щ – SHH, Ъ – ‘’, Ы – Y, Ь -’, Э – EH, Ю – JU, Я – JA
.Декодируйте фразу "tjomnaja noch’".
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 42, M = 9, P = 13, Q = 1500000
Вам необходимо декодировать некоторый текст S = 10001 00101 00011 01001 00100.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«агилнс»«иагнсл», K2=011001000101010100
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = ?*а??*а*?.
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 11, M = 7, P = 17, Q = 1000000
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(000111, 011000, 100001, 111011)
Сколько различных слов длины 3 можно построить в алфавите мощности 4?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *да?* .
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1111000 0110110 1011011 0111100 1000111 0110101
При передаче какого пакета возникла ошибка?
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«деикрт»«екртди», K2=101000011001100010
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 10
Какое слово в этом порядке имеет номер N?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 3, M = 7, P = 10, Q = 500000
Сколько слов длины 2 можно построить в алфавите мощности 2?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 43, M = 11, P = 10, Q = 750000
Вам необходимо декодировать некоторый текст S = 01111 00110 10000 00110 00011 01110 00101.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1100000000000 1101000001000 0010101000000 0101110101101
При передаче какого пакета возникла ошибка?
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 45, M = 10, P = 12, Q = 2500000
Число N в десятичной системе равно 2014. Введите две младшие цифры этого числа при записи в системе счисления с основанием P = 20.
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S имеет значение: «Мои любимые игры: Баскетбол, Волейбол!»
Определите значение строки S1 в результате выполнения следующих операций над строками:
k = IndexOf(S, «Баскетбол»);
S1 = Replace(S, k, 9, «Компьютерные игры» );
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 3; S = тор
Какой номер в этом порядке у слова S?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
01010 10100 11011 10111 11110 11011 11100
При передаче какого пакета возникла ошибка?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111000, 110001, 011110, 010010)
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *2*0*1*4.
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 19, M = 9, P = 7, Q = 800000
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
0011000000 0001010110 0111100001 1101010110 1011101100
При передаче какого пакета возникла ошибка?
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = л??о*.
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1100000000000 1101000001000 0010101000100 0101100101101
При передаче какого пакета возникла ошибка?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Строка S1 имеет значение: «Мои любимые игры:»
Строка S2 имеет значение: «Шахматы»
Строка S3 имеет значение: «Волейбол»
Определите значение строки S в результате выполнения следующих операций над строками:
S = S1 + « » + S2 + «, » + S3 + «!»
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1«веист»=«ствие», K2=011100010001000
Фирма «Все, что угодно» имеет предприятия в N странах, выпускающие различные виды продукции. Двоичный код товара содержит код страны, представленный минимально возможным числом битов, и код продукции. Код продукции состоит из M символов алфавита мощности P. Каждый символ кодируется минимально возможным набором битов. Код товара представляется целым числом байтов.
Пример: Число стран – 12. Для хранения кода страны требуется 4 бита. Код продукции состоит из 7 символов. Каждый символ – это цифра или одна из семи букв. Для хранения кода продукции потребуется 35 битов. Для хранения кода товара требуется 5 байтов.
За год предприятия фирмы выпустили Q единиц товарной продукции. Какую память требуется иметь для хранения всех кодов товаров?
Ответ укажите в мегабайтах с точностью до одного мегабайта, проведя округление в большую сторону.
N = 73, M = 6, P = 16, Q = 800000
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {м, о, р, с }; m = 4; S = морс
Какой номер в этом порядке у слова S?
Над числами определены арифметические операции. Над строками (указываются в кавычках) определены строковые операции:
Определите значение строки S в результате выполнения следующих операций над строками:
S = «Миша» + « + » + «Маша» + « = » + «любовь» + «!»
Греческий алфавит содержит 25 символов от \alpha до \omega. Слово, записанное в греческом алфавите, состоит из 2-х символов. Какова длина слова, полученного перекодировкой его в алфавит {0,1}?
Сколько различных слов длины 5 можно построить в алфавите мощности 2?
При передаче данных по надежным линиям связи вероятность появления двух ошибок крайне мала. Для обнаружения одной ошибки при передаче данных передаваемые пакеты снабжаются контрольной суммой.
В результате передачи получены следующие пакеты:
1111000 0110110 1011011 0111100 1000111 0110101
При передаче какого пакета возникла ошибка?
При передаче данных по линиям связи возможны ошибки передачи. Как правило, для надежных линий вероятность появления двух и более ошибок при передаче пакета данных мала. Используя избыточный код, можно не только обнаруживать ошибку передачи, как в случае контрольных сумм, но и исправлять ошибки. Такими свойствами обладает набор кодов, в котором расстояние по Хэммингу более или равно двум.
Определите расстояние по Хэммингу для данного набора кодов:
(111000, 110001, 011110, 010010)
Дан алфавит T. Алфавит упорядочен. В кириллице порядок известен – от А до Я, в латинице – от A до Z. Упорядочены и символы алфавита и в кодировке Unicode. Порядок символов в алфавите определяет порядок и на словах, порождаемых этим алфавитом. Этот порядок называется словарным или лексикографическим.
Построим в этом алфавите слова длины m. Число таких слов нетрудно посчитать. Пронумеруем эти слова, идущие в словарном порядке. Нумерация начинается с единицы.
T = {а, о, п, р, т}; m = 4; N = 620
Какое слово в этом порядке имеет номер N?
Сколько различных слов длины 6 можно построить в алфавите мощности 2?
Вам необходимо декодировать некоторый текст S - бф ьл. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S - ьэюья. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S - гшбю. Из агентурных источников стало известно, что:Текст записан в алфавите из 34 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 33 строчные буквы кириллицы. При кодировании использовался код Цезаря. Сдвиг неизвестен, но известно, что символ пробела при кодировании переходит в одну из букв алфавита (а, к или м). В результате декодирования получается слово русского языка.
В ответе укажите текст после декодирования.
Вам необходимо декодировать некоторый текст S = 10001 01011 01110 00011 01110.
Известно, что исходный текст записан в алфавите из 32 символов. Первым символом в этом алфавите идет символ «пробел» (пусто), а затем 31 строчная буква кириллицы, за исключением символов «ё» и «й».
Закодированный текст записан в двоичном алфавите {0, 1}. Символы исходного алфавита кодируются двоичными словами минимально возможной длины. Упорядоченность символов при кодировке сохраняется.
В ответе укажите текст после декодирования.
Примечание: для удобства восприятия закодированный текст разбит на группы по 5 символов.
Вам необходимо декодировать некоторый текст S.
Из агентурных источников стало известно, что:
Текст прошел двойное кодирование. При первом кодировании использовалась таблица кодировки Т1. При втором – символы алфавита заменялись двоичными словами минимально возможной длины. При этом кодировании известно, что в первой строке таблицы кодировки символы алфавита упорядочены и кодировка сохраняет упорядоченность.
Таблица кодировки Т1 попала в Ваши руки.
В ответе укажите текст после декодирования.
Пример. Таблица кодировки Т1: «аемпт» «тпаме». Пусть кодируется текст «темп». После первого кодирования он перейдет в текст «епам». После второго – в текст «001011000010»
Т1=«аезкр»«креза», K2=000100001011010
При поиске текстов, отвечающих некоторому образцу, для задания образца используются маски, содержащие специальные символы: * - соответствует произвольному тексту любой длины, в том числе пустому тексту длины нуль; ? – соответствует любому одиночному символу; D – соответствует цифре; L – соответствует литере – букве кириллицы или латиницы.
Примечание: далее любой текст произвольной длины будем называть словом.
Отметьте слова из данного списка, соответствующих маске S = *а??*а.
Сколько различных слов длины 3 можно построить в алфавите мощности 4?