Даны четыре примера (наблюдения) в трехмерном пространстве признаков: A(1;4;10), B(2;5;6), C(1;3;8) и D(2;4;8), при этом известно, что первый и третий примеры относятся к классу "1", а второй и четвертый – к классу "0". Проведите процедуру отбора признаков (feature selection) методом minimum redundancy maximum relevance (mRMR), используя логарифм по основанию 2. Укажите, какие признаки нужно оставить:
На электронную почту пришло письмо. Пусть X – бинарный признак, указывающий, содержит входящее письмо сочетание слов "вам оставили наследство" (=1), или нет(=0), а Y – класс письма, указывающий, спам это (=1), или нет (=0). Известно, что P(Y=1)=0,05, P(X=1|Y=1)=0,0001, P(X=1|Y=0)=0,00001, и в письме присутствует указанное словосочетание. Каким решающим правилом нужно воспользоваться – максимального правдоподобия (ML) или апостериорного максимума (MAP), чтобы определить, пришедшее письмо – спам или нет:
На электронную почту пришло два подозрительных письма, одно из них (A) содержало слово "лотерея", второе (B) – слова "лекарство" и "похудение". Дано, что спам составляет 3% писем, доля писем, где встречается слово "лотерея": спам - 0,04%, не спам – 0,01%; слово "лекарство": спам - 0,02%, не спам – 0,01%; слово "похудение": спам - 0,01%, не спам - 0,0005%. Пользуясь наивным байесовским классификатором (Naive Bayes) с правдоподобием Бернулли (BernoulliNB), определить, какие из полученных писем являются спамом.
Принцип Maximum Likelihood
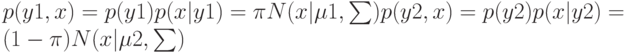
. Функция правдоподобия
![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png)
. Максимизируя

, в результате имеем одну из составляющих ?
В результате действия чего из знаменитой фразы "to be or not to be" может удалиться все содержимое?
Выберите ситуацию, при кластеризации которой, НЕ используется метод DBSCAN:
Для задачи функции активации - ограничить амплитуду выходного значения нейрона, чаще всего используется сигмоидальная (S-образная) функция(и) ?
Основный принцип, который используется в машинном обучении – это принцип:
Для оценки "натренированной" модели на эффективность ее применения, используется тестирование на независимой выборке. Какой из алгоритмов проверки "тренируется" на всем количестве данных, при условии многократного повторения?
Рассмотрим многослойный персептрон, состоящий из вытянутых в линейную цепочку 10 нейронов (один из них входной, один выходной, а 8 образуют 8 скрытых слоев). Для коррекции весов используется алгоритм обратного распространения ошибки (back propagation). Функция ошибки среднеквадратическая. Значения весов и ошибка на выходе не превышают по модулю единицы. Выберите, при каких значениях сигнала на входе градиент на входе может превысить 0,0001.

