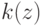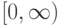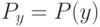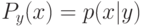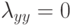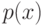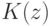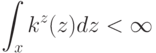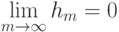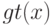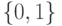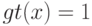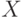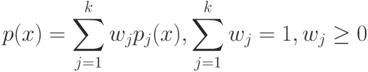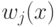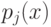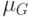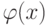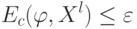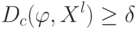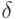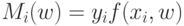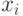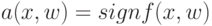Какой получится алгоритм, если  определить как наибольшее число, при котором ровно
определить как наибольшее число, при котором ровно 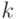 ближайших соседей объекта
ближайших соседей объекта  получают нулевые веса:
получают нулевые веса: 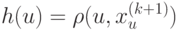 .
.
(Отметьте один правильный вариант ответа.)
Варианты ответа
![a(u;X^l,k) = \arg\max_{y \in Y}\sum_{i=1}^k[y_u^{(i)} = y]k(\frac{\rho(u,x_u^{(i)})}{\rho(u,x_u^{(k+1)})})](https://intuit.ru//sites/default/files/tex_cache/39639fc70cced9a2d79502e4dbc6e208.png)
![a(u;X^l,k) = \arg \max_{y \in Y} \sum_{i=1}^k[y_u^{(i)} = y]](https://intuit.ru//sites/default/files/tex_cache/6d08fe23f9e0382fdbe42e65a25f39d8.png)
![a(u;X^l,k) = \arg \max_{y \in Y} \sum_{i=1}^l [y_u^{(i)} = y]w_i](https://intuit.ru//sites/default/files/tex_cache/1a58555e4796240786678f8e96b69294.png)
![a(u;X^l,h) = \arg \max_{y \in Y} \sum_{i=1}^l [y_u^{(i)} = y]k(\frac{\rho(u,x_u^{(i)})}{h})](https://intuit.ru//sites/default/files/tex_cache/4b09f0f3850bb174429335a35805ae0b.png)