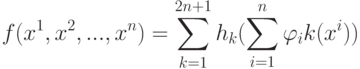Плотность распределения на 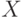 имеет вид смеси
имеет вид смеси 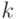 распределений
распределений 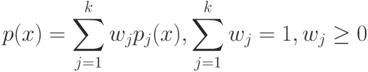 , где
, где 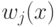 - это:
- это:
(Отметьте один правильный вариант ответа.)
Варианты ответа

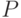
порог
функция правдоподобия -ой компоненты смеси;
априорная вероятность функции правдоподобия(Верный ответ)
вектор параметров 
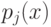


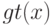
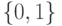

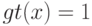
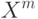
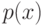
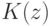
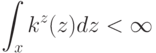


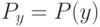
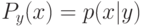
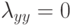

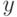
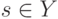

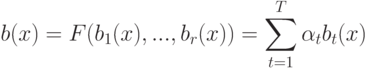
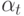



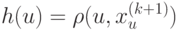
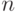
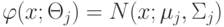
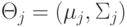

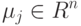
![[0,1]^n](https://intuit.ru//sites/default/files/tex_cache/0dca0690a28084bef5b302e338fa1468.png)