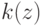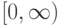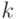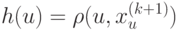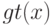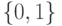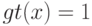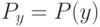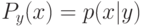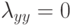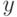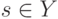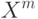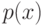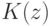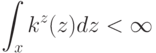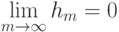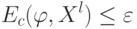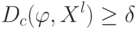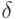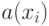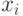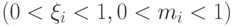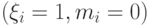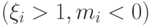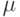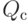Что получится, если дискриминантная функция определяется как скалярное произведение вектора 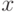 и вектора параметров
и вектора параметров 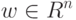 ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
гауссовская модель априорного распределения;
линейный классификатор;(Верный ответ)
гиперпараметр.
априорное распределение Лапласа;