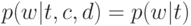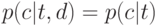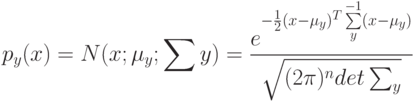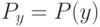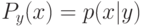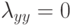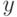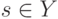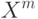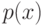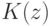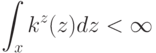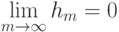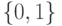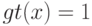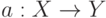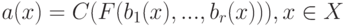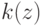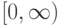Что характеризует гипотеза условной независимости вида: 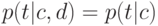 ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
классификация документа d зависит не от самого документа, а только от его тематики;
распределение слов полностью определяется тематикой документа и не зависит от самого документа и его классов;
тематика документа d зависит не от самого документа, а только от того, каким классам он принадлежит;(Верный ответ)
ничто из выше перечисленного не является характеристикой гипотезы условий независимости.