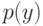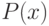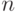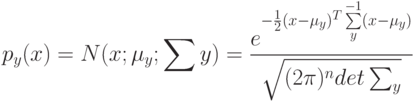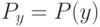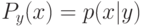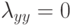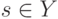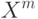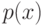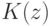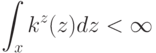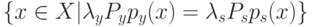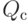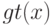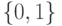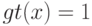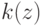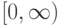В формуле совместной плотности функцией априорной вероятности класса будет функция: (Отметьте один правильный вариант ответа.) Варианты ответа (Верный ответ)
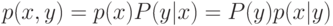 функцией априорной вероятности класса
функцией априорной вероятности класса 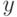 будет функция:
будет функция: