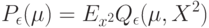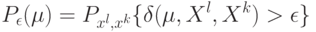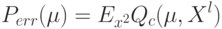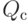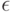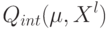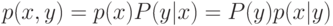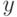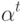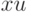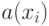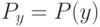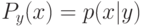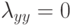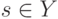Как будет выглядеть формула вероятности ошибки в интерпретации обобщающей способности метода ? (Отметьте один правильный вариант ответа.) Варианты ответа ; ;(Верный ответ) ;
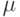 ?
?