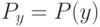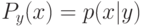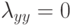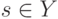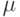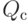Что будет градиентным шагом в формуле ? (Отметьте один правильный вариант ответа.) Варианты ответа . ;(Верный ответ) ; ;
![w_m:=w_m + \eta(x_i - w_m)[a(x_i) = m]](https://intuit.ru//sites/default/files/tex_cache/da86b4a213058b68c1dfd78065a42803.png) ?
?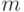
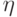
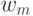
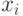


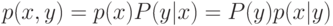
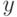
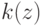
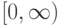


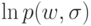

![a(u; X^l,h) = \arg \max_{y \in Y} \sum_{i=1}^l[y_n^{(i)}=y] k(\frac{\rho(u,x_u^{(i)})}{h})](https://intuit.ru//sites/default/files/tex_cache/51a55dbfe7e526a8e5547f4ca8ac785d.png)