
Как называется параметр  в формуле
в формуле ![a(u; X^l,h) = \arg \max_{y \in Y} \sum_{i=1}^l[y_n^{(i)}=y] k(\frac{\rho(u,x_u^{(i)})}{h})](https://intuit.ru//sites/default/files/tex_cache/51a55dbfe7e526a8e5547f4ca8ac785d.png) ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
ширина окна;(Верный ответ)
усредненное обучение;
вектор матожидания.
метрический классификатор;
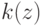
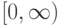





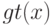
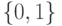

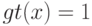
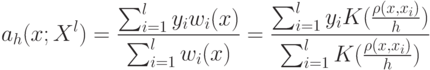

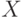
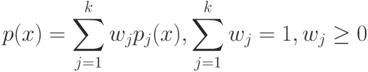
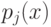
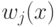
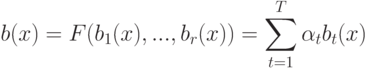
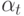

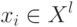
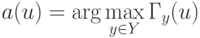
![w(i,u) = [i \le k]w_i; a(u;X^l,k) = \arg \max_{y \in Y}\sum_{i=1}^k [y_{(n)}^{(i)} = y]](https://intuit.ru//sites/default/files/tex_cache/f5fddb5dc5e005733b611f4d0cef6486.png)