В формуле линейной модели "W" означает следующее 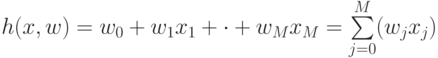
(Отметьте один правильный вариант ответа.)
Варианты ответа
Базисные функции;
Вектор весов;(Верный ответ)
Обучающий объект;

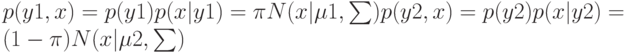 . Функция правдоподобия
. Функция правдоподобия ![$p(Y,X|\pi ,\mu 1,\mu 2,\sum)=N\qquad n=1\qquad [\pi N(x|\mu 1,\sum)]\quad yn[(1-\pi)N(x|\mu 2,\sum)]\quad 1-yn.$](https://intuit.ru//sites/default/files/tex_cache/74c536c4680380e54b35098ad1bc64c9.png) . Максимизируя
. Максимизируя  , в результате имеем одну из составляющих ?
, в результате имеем одну из составляющих ?