В формуле линейной модели "W" означает следующее
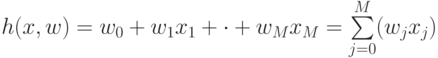
Что из этого является видом модели классификации?
Напишите название регрессии, используемой для предсказания вероятности возникновения некоторого события путём подгонки данных к логистической кривой
Уважите преимущества вероятностных моделей (дискриминативные и генеративная модели ) ?
Согласно стандартной модели зрительной коры головного мозга, считается что?
Имеются бактерии с двумя количественными признаками x1, x2, строится логистическая регрессия для определения вероятности, с которой бактерии относятся к одному из двух классов (видов) - y1 или y2. Предполагается нормальное распределение условных вероятностей, соответственно модель получается линейной, и p(y1|x)=1/(1+exp(-(w1*x1+w2*x2+w0))). В результате обучения были найдены следующие значения: w0=1, w1=3, w2=-4. Найдите, с какой вероятностью бактерия с признаками x1=1, x2=1 относится ко второму классу. Ответ укажите с точностью до одного знака после запятой:
Дан единичный квадрат с координатами вершин (0;0), (0;1), (1;1), (1;0). При этом первая и третья вершины относятся к классу "-1", а вторая и четвертая – "1". Требуется построить классификатор, получающий на входе координату вершины, а на выходе дающий метку класса (задача XOR). Функция потерь определяется числом неправильно классифицированных вершин с учетом их веса. В результате применения алгоритма AdaBoost были построены три модели со следующими разделяющими границами: (1) прямая, проходящая через точки (1/2;0) и (0;1/2), (2) прямая, проходящая через точки (1/2;1) и (1;1/2), (3) прямая, проходящая через точки (1/2;1) и (0;1/2). Изначально веса вершин одинаковы и равны 1/4, далее они пересчитываются в соответствии с алгоритмом. Укажите получившиеся веса первой, второй и третьей модели соответственно:
Для 10 значений количественного признака X 1; 2; 3; 4; 5; 6; 7; 8; 9; 10 даны соответствующие значения Y: 2,5; 3,1; 0,4; -2,3; -3,2; -0,8; 2,0; 3,0; 1,2; -2,0. Функция регрессии ищется в виде Y=A*sin(X), A=3,174 (квадратичная функция потерь). Для более стабильного результата был применен алгоритм бэггинга (bagging). С помощью датчика случайных чисел были сделаны четыре выборки из указанных 10 примеров с возвращением (указаны только значения X): {1; 1; 2; 3; 4; 6; 8; 8; 10; 10}, {2; 2; 3; 4; 5; 7; 7; 8; 9; 10}, {1; 3; 3; 3; 6; 6; 7; 8; 8; 9}, {4; 4; 4; 5; 5; 5; 6; 9; 9; 9}. Для каждой из четырех выборок вычислите коэффициент A при sin (X) с квадратичной функцией потерь. В качестве ответа укажите среднее арифметическое этих четырех значений с точностью до двух знаков после запятой.
В обобщенной формуле обучения модели learning= representation +Evaluation+ optimization критериями Evaluation являются
Для оценки "натренированной" модели на эффективность ее применения, используется тестирование на независимой выборке. Какой из алгоритмов проверки "тренируется" на всем количестве данных, при условии многократного повторения?

