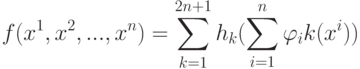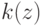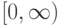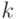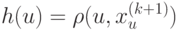Верно ли, что метод 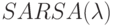 не принимает в расчет все будущие ситуации вплоть до конца эпизода при выполнении дублирования?
не принимает в расчет все будущие ситуации вплоть до конца эпизода при выполнении дублирования?
(Отметьте один правильный вариант ответа.)
Варианты ответа
Да
Нет(Верный ответ)



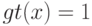
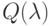
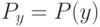
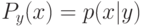
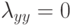

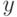
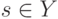

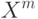
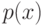
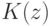
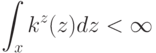

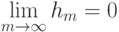

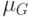


![[0,1]^n](https://intuit.ru//sites/default/files/tex_cache/0dca0690a28084bef5b302e338fa1468.png)