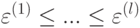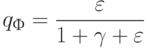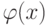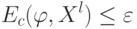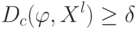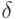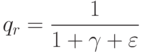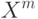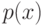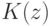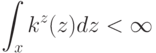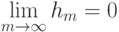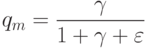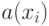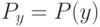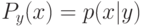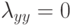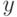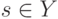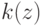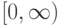Если используется квартическое ядро  , где
, где 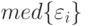 - медиана вариационного ряда ошибок, то это называют:
- медиана вариационного ряда ошибок, то это называют:
(Отметьте один правильный вариант ответа.)
Варианты ответа
мягкой фильтрацией;(Верный ответ)
робастными;
жесткой фильтрацией;
скользящими.