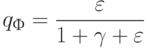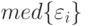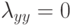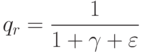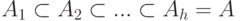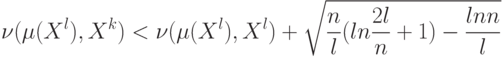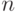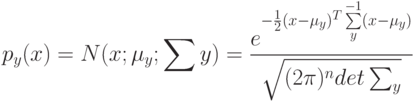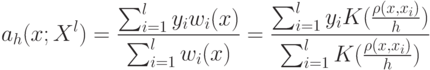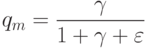Что показывает величина  ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
проекцию на главные компоненты;
значение m, при котором происходит резкий скачок: 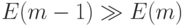 , при условии, что
, при условии, что  уже достаточно мало;
уже достаточно мало;
эффективную размерность задачи.
какая доля информации теряется при замене исходных признаковых описаний длины n на более короткие описания длины m;(Верный ответ)