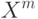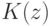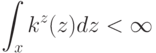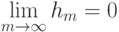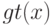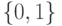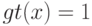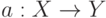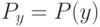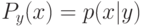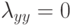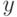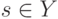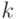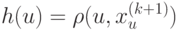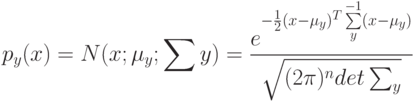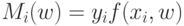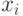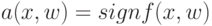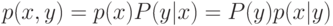На локальной аппроксимации плотности 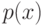 в окрестности классифицируемого объекта
в окрестности классифицируемого объекта  основано:
основано:
(Отметьте один правильный вариант ответа.)
Варианты ответа
восстановление смеси плотностей
эмпирическая оценка плотности
непараметрическое восстановление плотности(Верный ответ)
параметрическое восстановление плотности