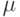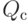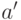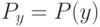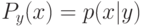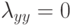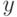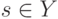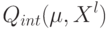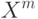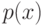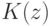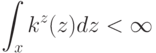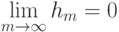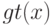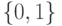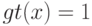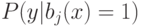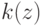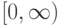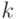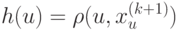Если при переобучении: на  всё хорошо, на
всё хорошо, на  всё плохо, то это проявление:
всё плохо, то это проявление:
(Отметьте один правильный вариант ответа.)
Варианты ответа
мультиколлинеарности(Верный ответ)
байесовского решающего правила
вероятностного распределения
гаусовского распределения