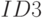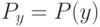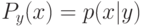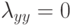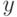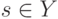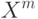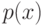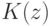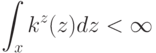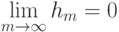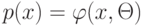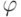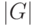К чему приводит уменьшение параметра  при оптимизации сложности решающего списка?
при оптимизации сложности решающего списка?
(Отметьте один правильный вариант ответа.)
Варианты ответа
к покрытию всей выборки;
к снижению числа ошибок на обучении;(Верный ответ)
к невозможности найти правило с информативностью выше  по остатку выборки.
по остатку выборки.