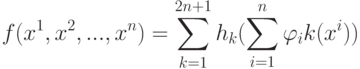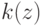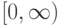Верно ли, что по мере увеличения сложности модели внутренний критерий возрастает? (Отметьте один правильный вариант ответа.) Варианты ответа Да Нет(Верный ответ)
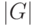 внутренний критерий возрастает?
внутренний критерий возрастает?
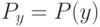
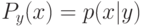
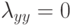

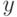
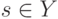


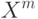
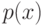
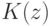
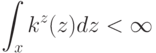

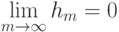



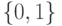

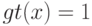
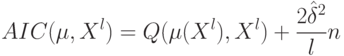

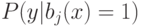

![[0,1]^n](https://intuit.ru//sites/default/files/tex_cache/0dca0690a28084bef5b302e338fa1468.png)