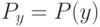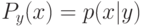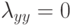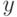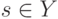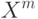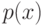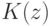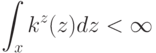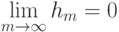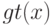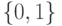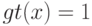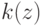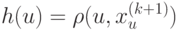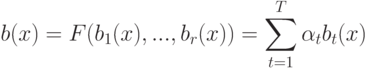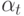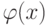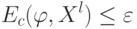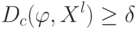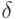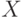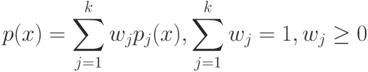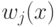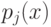На что, из ниже перечисленного, влияют параметры  и
и  ?
?
(Отметьте один правильный вариант ответа.)
Варианты ответа
на количество получаемых конъюнкций;(Верный ответ)
на добавление конъюнкций 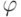 в список.
в список.
на оценивание малоинформативных конъюнкций;