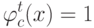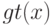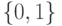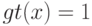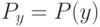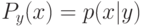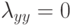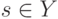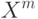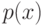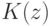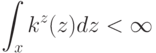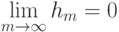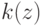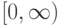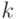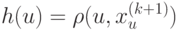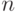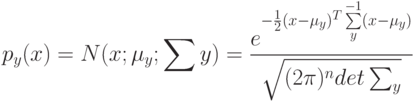Выберите верный вариант. Если для каждого класса 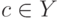 построено множество логических правил, специализирующихся на различении объектов данного класса
построено множество логических правил, специализирующихся на различении объектов данного класса 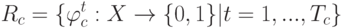 и если
и если 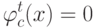 , то:
, то:
(Отметьте один правильный вариант ответа.)
Варианты ответа
правило 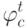 воздержится от классификации объекта Х;(Верный ответ)
воздержится от классификации объекта Х;(Верный ответ)
правило описывает объект  к классу С;
к классу С;
правило отнесет объект к другому классу.